Lec 13: Process Lifecycle: Process Creation and Termination
Table of Contents
1 Unix Processes
A process is an executing instance of a program. We have been discussing processes in one form or another throughout the class, but in this lesson we dive into the lifecycle of a process. How does a process get created? How is it managed? How does it die?
For starters, let's return to the definition of a process: an executing instance of a program. A program is the set of instructions for how a process operates when run, while a process is a current instance of that program as it executes. There can be multiple instances of the same program running; for example, multiple users can be logged into a computer at the same time, each running a shell, which is the same program with multiple executing instances.
A process is also an Operating System abstraction. It's a way to manage varied programs and contain them within individual units. It is via this abstraction that the O.S. can provide isolation, ensuring that one process cannot interfere with another. A process is also the core unit of the O.S. resource of Process Management which the main goal is to determine which process has access to the CPU and at what time.
In this lesson, we are going to trace the life and death of a Unix process, from the first nubile invocation to the final mortal termination. We'll begin at the end, with death, and work backwards towards birth. Throughout this lesson, we'll use the diagram below to explain these concepts. You can find a version of this diagram in APUE on page 201, Section 7.3.
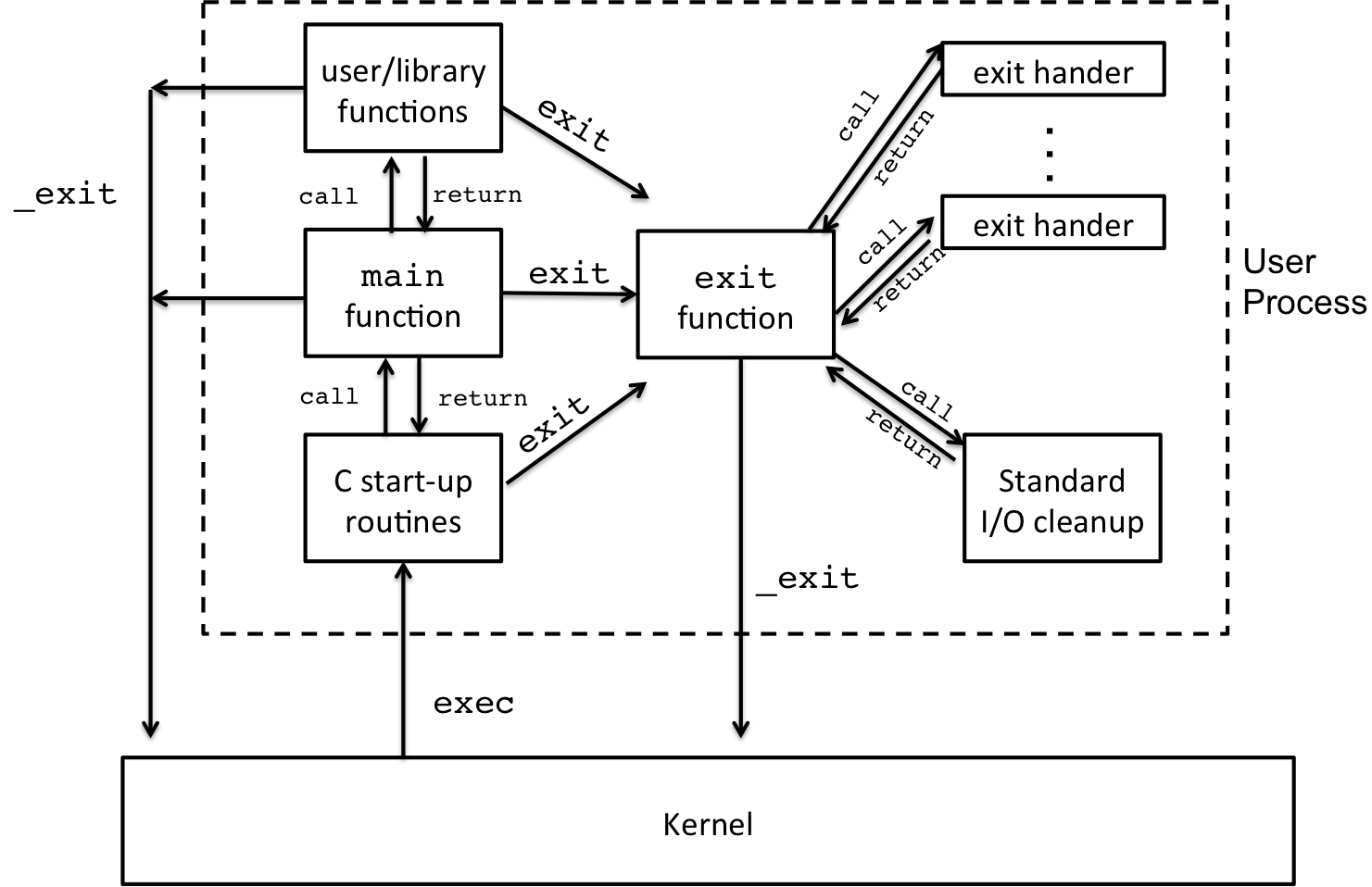
Figure 1: C Program Life Cycle: Invocation through Termination
2 The Death of a Process
Let's start with a fairly simple question: How do we make a program
terminate in code? There are illogical ways to do this –
dereferencing NULL and forcing a segfault – but the standard
way to do this is to allow the main() function to return. What do
we do if want our program to logically terminate from another point
in the program, somewhere other than main()? We need a separate
mechanism to do that, and the solution is an exit call, like we did
in bash programming.
2.1 exit() and _exit() and _Exit()
There are three ways to forcefully exit a program:
_exit(): System calls that request the O.S. to terminate a process immediately without any additional code execution.exit(): C Standard Library exit procedure that will cleanly terminate a process by invoking additional code as requested by the user and to manage ongoing I/O._Exit(): C Standard Library exit procedure that will immediately terminate a process, essentially a wrapper to_exit()
To better understand these differences we can refer back to the diagram:
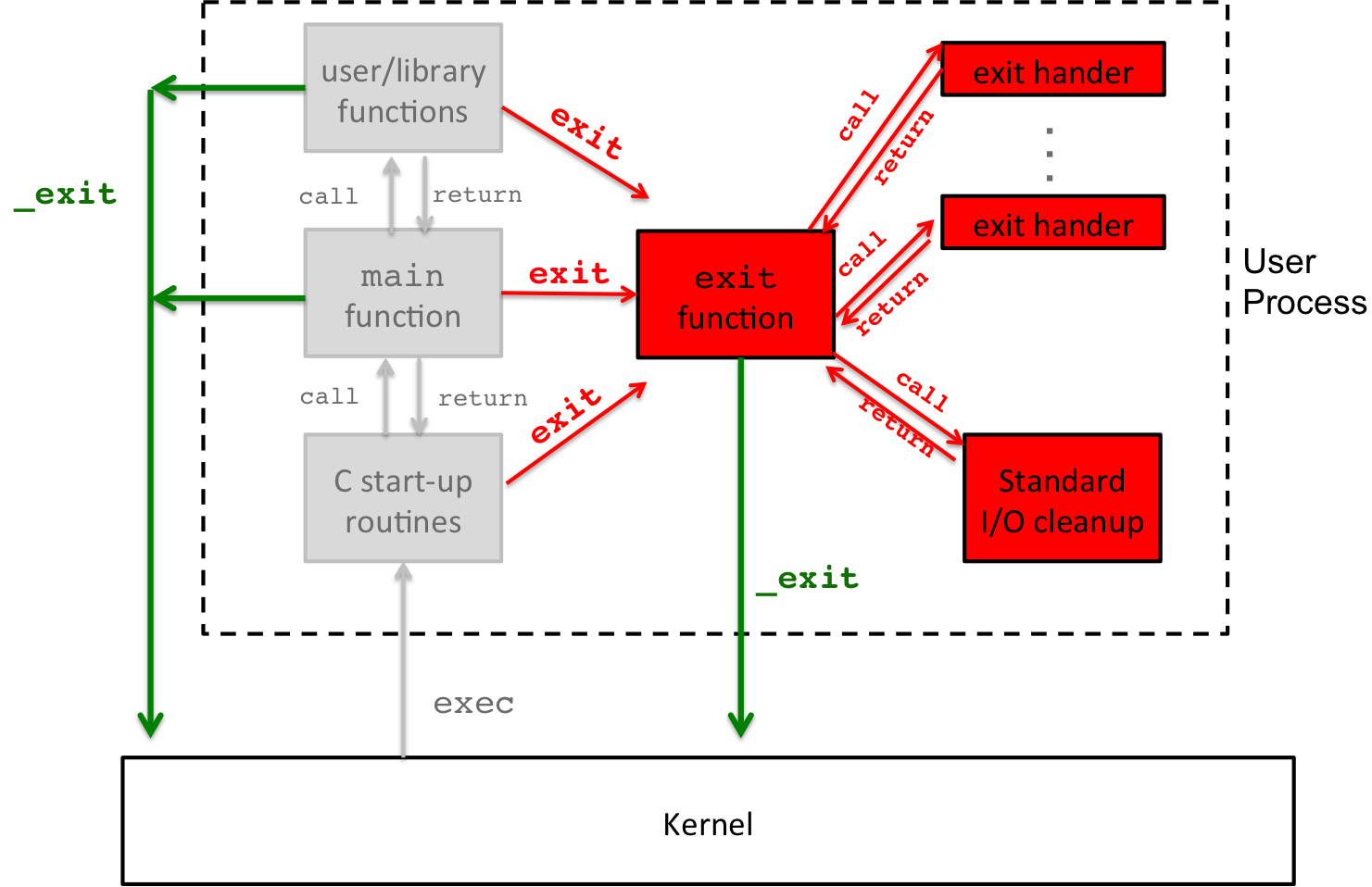
Figure 2: C Program Life Cycle: exit() vs. _exit()
The flow of the green arrows refer to the system call _exit()
which leads to direct termination of the process. Once a process is
terminated, the kernel is invoked to choose which process should run
next, which is why flow points towards the kernel. However, a call
to exit() (no underscore), at any point in the program execution,
starts a separate set of actions, which include running exit
handlers and I/O procedures. This is indicated in red in the
diagram, and eventually, once exit procedures are complete, exit()
calls _exit() to do the final termination. Not pictured is
_Exit(), which has the same action as _exit().
Like many of the O.S. procedures we've been discussing so far in this class, the exit procedure has both a system call version and a library call version. In general, when you program you will likely only use the library function, which is fine, but to be an effective programmer you need to understand the underlying O.S. procedures that enable the library routines.
2.2 I/O Buffering and Exit Procedures
One aspect of the standard library exit procedure is to handle I/O buffering that occurs within the C standard library. This depicted in the diagram like so:
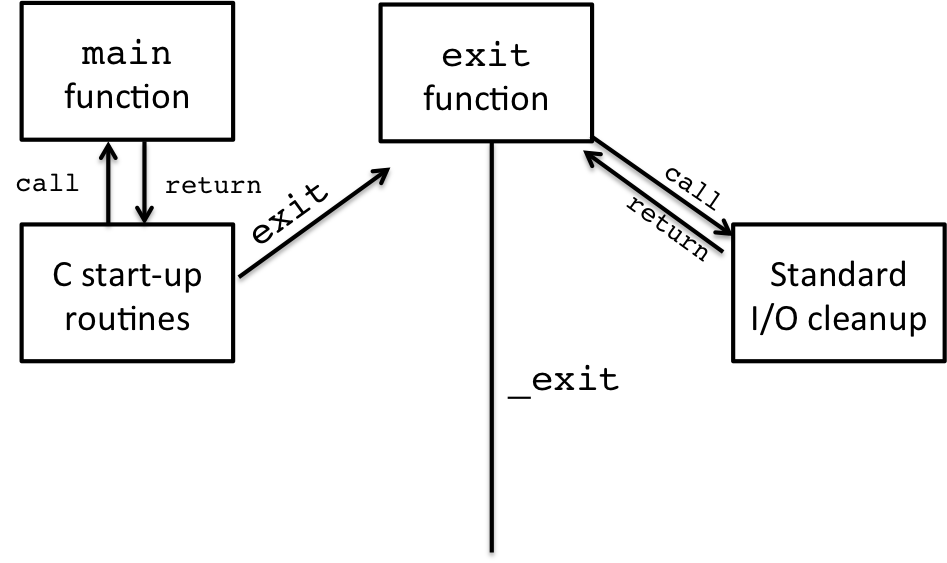
Figure 3: C Program Life Cycle: Standard I/O Cleanup
I/O bufferring in the C standard library is an attempt to limit the
number of system calls, i.e., calls to write(), which are
costly. A system call requires that the entire process be paused,
saved, and swapped out in favor of the OS, which then performs the
action, and once complete, the user process must be swapped back in
to complete its operation. Just enumerating all the steps of a
context switch is exhausting, and it is an expensive operation, one
that should be avoided except when absolutely necessary.
Buffering is one way to avoid excessive calls. When you call
printf() or another standard I/O library function that is printing
to the terminal or a file, the print does not occur right
away. Instead, it is buffered, or temporarily stored and waiting
to be completed. A print will become unbuffered whenever the buffer
is full, e.g., there is enough bytes to write and cannot store any
more, or when a line completes, as defined by printing a newline
symbol.
So if we were to look at the hello-world program:
int main(){ printf("Hello World!\n"); }
The printing of "Hello World!" includes a new line symbol, and thus the buffer is flushed and "Hello world!" is printed to the terminal. However, consider this version of the hello-world program:
int main(){ printf("Hello World!"); }
This time there is no newline, but "Hello World" is still printed to the terminal. How?
When the main() function returns, it actually returns to another
function within the C startup routines, which calls exit(). Then
exit() will perform a cleanup of standard I/O, flushing all the
buffered writes.
However, when you call _exit(), buffers are not cleared. The
process will exit immediately. You can see the difference between
these two procedures in these two programs:
/*exit_IO_demo.c*/ #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(){ // I/O buffered since no newline printf("Will print"); exit(0); //C standard exit }
/*_exit_IO_demo.c*/ #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(){ // I/O buffered since no newline printf("Does not print"); _exit(0); //immediate exit! }
You do not need to rely on the exit procedures to clear the I/O
buffers. Instead, you can directly flush the buffers with fflush()
library function. For example:
int main(){ // I/O buffered since no newline printf("Will print once flushed"); fflush(stdout); // flushing stdout's buffer, printing _exit(0); //immediate exit! }
The fflush() function takes a FILE * and will read/write all
data that is currently being buffered. There is also an analogous
function, fpurge(), which will delete all data in the buffers.
2.3 Changing I/O Buffering policy
The buffering policy at the process level varies by input/output
mechanisms. For example, let's consider a program that prints to
stderr instead of stdout.
/*_exit_IO_stderr.c*/ #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(){ // I/O not buffered for stderr fprintf(stderr, "Will print b/c stderr is unbuffered"); _exit(0); //immediate exit! }
In some ways, this is good policy. You want errors to be reported
immediately, not when it is most convenient for the buffer. There
is a side effect, however, writes to stderr are more expensive
since it requires an immediate context switch.
We can change the policy for how an input/output stream is
buffered. By default, stdout and stdin is line buffered which
means that input and output is buffered until a newline is
read/written. stderr is unbuffered, as described above. There
is also a third choice, fully buffered, which means writes/reads
occur once the buffer is full.
The library call to change the buffering policy is setvbuf(),
which has the following function declaration:
int setvbuf(FILE *stream, char *buf, int mode, size_t size);
You select which input/output stream is affected, such as stderr
or stdout, and you can also provide memory for the buffer with
its size. The mode option can have the following choices:
_IONBFunbuffered : data is written immediately to the device via the system callwrite()_IOLBFline buffered : data is written to the device usingwrite()once a newline is found or the buffer is full_IOFBFfully buffered : data is only written to the device usingwrite()once the buffer is full
In general, you do not need to specify a new buffer, instead just
want to affect the mode. For example, if we want to set stderr to
be line buffered, we can alter the program from above like so, and
the result would be that it would no longer print
/*_exit_IO_setvbuf.c*/ #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(){ //stderr is now Line buffered setvbuf(stderr, NULL, _IOLBF, 0); // I/O now buffered for stderr fprintf(stderr, "Will NOT print b/c stderr is now line buffered"); _exit(0); //immediate exit! }
2.4 atexit() Exit Handlers
So far, we've seen within the context of I/O buffering, that the
exit() procedure will perform actions before executing the final
exit, with _exit(). What if you wanted to add an additional exit
processing? You do that with exit handlers.

Figure 4: C Program Life Cycle: exit handlers
Exit handers are functions that are automatically called whenever
a program is exit()'ing. You can register, in general, 32 exit
handlers using the atexit() library function. The order each exit
handler executes is in reverse order of their registration. Consider
the below program
/*exit_handler_demo.c*/ #include <stdio.h> #include <stdlib.h> void my_exit1(){ printf("FIRST Exit Handler\n"); } void my_exit2(){ printf("SECOND Exit Handler\n"); } int main(){ //exit handers execute in reverse order of registration atexit(my_exit1); atexit(my_exit2); //my_exit2 will run before my_exit1 return; //implicitly calls exit() }
The output of this program is:
#> ./exit_hander_demo SECOND Exit Handler FIRST Exit Handler
A couple of other things to note here is that the argument to
atexit() is a function. This is the first time we are using a
function pointer, or a reference to a function. We will do something
similar later in the class when setting up signal handlers, again
registering a function to be called when an event occurs.
2.5 Exit Statuses
The last bit of the exit() puzzle is exit status. Every program
exits with some status. This status can then be checked to learn
information about the execution of the process, for example, did
it exit successfully or on failure or error?
You can set the exit status of a program via the various exit()
calls:
_exit(int status); exit(int status); _Exit(int status);
Additionally, the return value of main() implicitly sets the exit
status. Convention indicates the following exit status:
- 0 : success
- 1 : failure
- 2 : error
We've seen this before when programming with bash scripting. Recall
that an if statement in bash executes a program:
if cmd #<--- executes command and checks exit status then else fi
When cmd succeeds, i.e., returns with exit status 0, then the
then block is executed. If the cmd fails or there was an error,
the else block is executed. The special variable, $?, also
stores the exit status of the last executed program.
An exit status actually is more than just the argument to
_exit(). The kernel also prepares a termination status for a
process, one of those parts is the exit status. The termination
status also contains information about how the program
terminated, and we will concern ourselves more with termination status
when we discuss process management.
3 The Birth of a Process
Now that we have good understanding about the death of a process, let's look at the birth of a process.
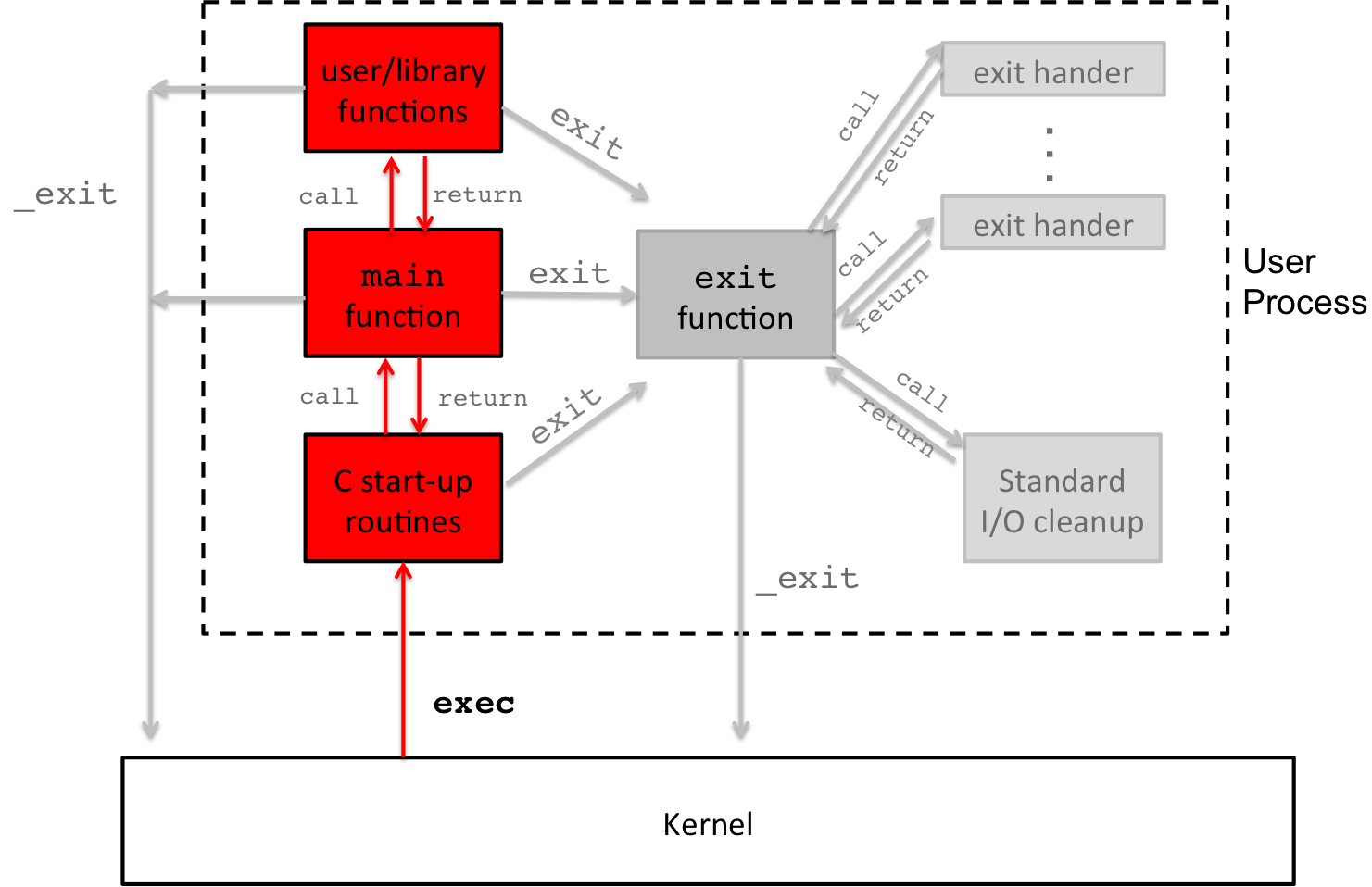
Figure 5: C Program Life Cycle: exec and startups
Forever, you have always learned that a program begins in main(),
but that's not exactly true. The part of the program you wrote
starts in main(), but, in fact, when you compile a program, there
is a set of additional functions that will execute first to set up
the environment. Once those complete, main() is called, and when
main() returns, it returns to those startup routines, which
eventually calls exit() … and we already know how that story
ends.
There is a more fundamental questions that we are not addressing:
How does a program actually load and execute as a process? This is
accomplished with the exec family of system calls, in particular
execv() and
3.1 Exec System Calls
The exec family of system calls simply loads a program from
memory and executes it, replacing the current program of the
process. Once the loading of instructions is complete, exec will
start execution through the startup procedures. We'll just discuss
the execv() system call, which has the following function
definition. Read the manual page to find the other forms of exec,
including execve() and execvp().
int execv(const char *path, char *const argv[]);
execv() takes a path to a program, as it lives within the file
system, as well as the arguments to that program. It's easier to
understand by looking at an example. The program below, will
execute ls.
/* exec_ls.c*/ #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(int argc, char * argv[]){ //arguments for ls char * ls_args[2] = { "/bin/ls", NULL} ; //execute ls execv( ls_args[0], ls_args); //only get here if exec failed perror("execve failed"); return 2; //return error status }
The execv() system call takes a path to the program, in this case
that is "/bin/ls", as well as an arg array. For this exec, the only
argument is the name of the program, ls_args[0]. You might notice
that the arguments to execv() match the arguments to main() with
respect to the argv array, and that's intentional. In some ways, you
can think of an exec calling the main() function of the program
directly with those arguments. You have to NULL the last argument so
that exec can count the total arguments, to set argc.
For example, we can extend this program to take an argument for ls
where it will long list the contents of the directory /bin. If we
were to call ls from the shell to perform this task, we would do so
like this:
ls -l /bin
We can translate that into an argv array with the following values:
//arguments for ls, will run: ls -l /bin char * ls_args[4] = { "/bin/ls", "-l", "/bin", NULL} ; // ^ ^ ^ // ' | | // Now with an argument to ls -'------'
In this case, ls_argv has 3 fields set, not including NULL. We can
now pass this through to exec:
/*exec_ls_arg.c*/ #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main(int argc, char * argv[]){ //arguments for ls, will run: ls -l /bin char * ls_args[4] = { "/bin/ls", "-l", "/bin", NULL} ; // ^ ^ ^ // ' | | // Now with an argument to ls -'------' //execute ls execv( ls_args[0], ls_args); //only get here if exec failed perror("execve failed"); return 2; //return error status }
Another thing to note is that upon success, an exec does not
return. Instead, the whole program is replaced with the exec'ed
program, when the exec'ed program returns, that's the final
return. To check if an exec fails, you don't need an if statement.
3.2 Creating A New Processes
There is still something missing. We understand how to execute a
new program, but we haven't actually discussed how we create new
processes. New processes are created by duplicating another
process, this is called forking, and we use the fork() system
call to request the operating system.
A fork() will create an exact copy of the process from which is
called from, a parent and a child. Each is now executing on its own
in parallel. In the child process, after the fork, it can now call
exec() which will replace the code inherittd from the parent with
a program, and thus the lifecycle is complete. We will save
further discussion of fork() for the lab.