UNIT 4: Trees
Table of Contents
1 Introducing Trees
1.1 Trees!
First, the mathematical definition of a Tree. A Graph is any set of vertices and a set of edges that connect vertices. A /cycle /is a path in a graph such that you can arrive back at a vertex without re-using any edges. A connected graph, is a graph where a path exists between all possible pairs of vertices. Finally, any connected graph that has no cycles is a Tree.
Well, that's not very interesting. Here's an example.
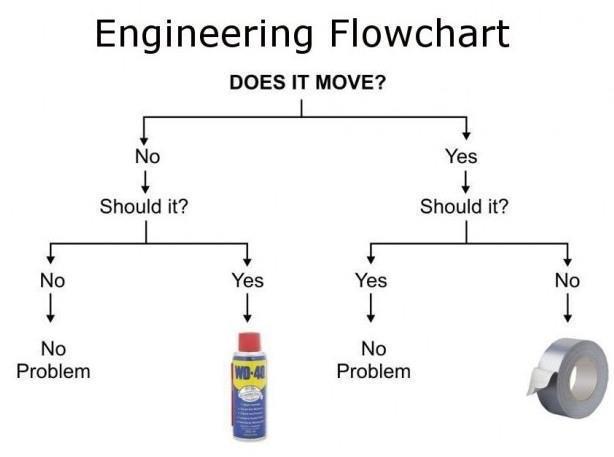
This is known as a decision tree. You see that a single node is at the top ("Does it move?"). This is the root. The root has two branches, to "No, should it?" and "Yes, should it?" Each of nodes also has two branches, one to "No/Yes, No problem," and the other to "No/Yes, WD-40/Duct Tape." Since every node in the three has two branches, it's called a binary tree.
Here are some definitions of terms that we use to describe the Nodes (or elements) of Trees:
- Node : an element of the tree
- Root : The single element at the top of the tree
- Parent : A node's parent is the node immediately above it. Every node, except the root, has exactly one parent.
- Child : A node's children are the nodes immediately below it. In a binary tree, every node as at most 2 children
- Sibling : Two nodes are siblings if they have the same parent
- Ancestor : Parent, or parent's parent, or etc.
- Leaf : A node with no children
- Internal Node : A node with at least one child, every node is either a leaf or internal node.
- Subtree : A portion of a tree that is, itself, a tree.
- Depth : The depth f a node is the number of edges that have to be traversed to encounter the root.
- Height : The most number of edges on any path from the root to a leaf. This is the same as the maximum depth of any node in the tree. A tree with one node (the root node!) has a height of 0. An empty tree has a height of -1.
- Branching Factor : The maximum number of children for a node is the branching factor; for example, a binary tree has a branching factor of 2.
1.2 Implementing Trees
So what does this look like in Java? We'll write this for a binary tree, or a tree where each node has up to two children.
public class Tree<T> {
private class Node {
public Node left = null;
public Node right = null;
public T data;
public Node(T d) {
data=d;
}
}
private Node root = null;
// constructors, some other methods too...
One of the methods we would like to write is the height() to get the
height of the tree. As above, height is defined as the maximum depth
of any node. To do that calculation, we should think recursively.
Consider that the height of the full tree is the maximum of the heights of the two subtrees beneath the root where the root's children are the sub-root of the subtree. And then within each of those subtrees, it is the maximum of the heights of the two sub-subtrees, and so on.
This leaves us with a nice recursive method like so:
public int height() {
return heightFrom(root);
}
private int heightFrom(Node n) {
if (n == null) return -1;
int lh = heightFrom(n.left);
int rh = heightFrom(n.right);
return Math.max(lh, rh) + 1;
}
}
Now, consider writing this same method iteratively. How might you do it? Well, we could use a Stack or Queue to do some tracking of heights to ensure we've traversed all the paths, but it will get ugly really quickly. Regardless, it will definitely NOT be 4 lines of code!
This is one of the many reasons that recursion is so important. It allows us to express fairly complex routines compactly and with clarity. So, if you are still struggling to understand recursion, be sure to ask questions because these examples will continue to come about.
2 Tree Traversals
Just like we needed to know how to traverse a Linked List, we need to know how to traverse a Tree. In a Linked List, the work we were doing to each Node could come either before or after the recursive call; this determined whether that work was done from the front of the list to the back, or from the back to the front. We have a similar concept here for trees, we just have more options.
2.1 Preorder Traversal
In preorder traversal, we have the rule that the node we're looking at must be visited before its children; there are no rules as to the order of its children, or grandchildren. In the following code, I'm going to use <code>process()</code> in place of whatever work you're doing to each node (maybe you're printing each data point, or whatever). Preorder traversal looks like this:
preorder(Node n) {
process(n.data);
for( Node child : n) //for each child of n
preorder(c);
}
2.2 Postorder Traversal
In postorder traversal, the node we're looking at is visit after its children. It looks like this:
postorder(Node n) {
for(Node child : n) //for each child of n
postorder(cc);
process(n.data);
}
2.3 Inorder Traversal
We're going to deal with a lot of binary trees in this class. With a binary tree, we also have the option of Inorder Traversal, which is where you visit the left subtree first, then this node, then the right subtree
inorder(Node n) {
inorder(n.left);
process(n.data);
inorder(n.right);
}
Consider the following tree:
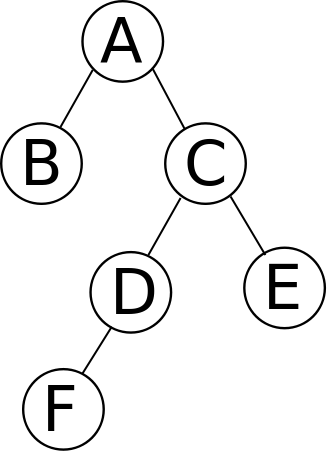
These traversals would visit the nodes in the following order:
- Preorder: A B C D F E
- Inorder: B A F D C E
- Postorder: B F D E C A
2.4 Level-order Traversal
Level order traversal is easy to do visually, but harder to do computationally. Unlike preorder and postorder traversals which are depth-first in nature (they descend all the way to the leaves of one subtree before moving on to the next), a level-order traversal is breadth-first. And in order to search in a breadth-first manner, we need a queue:
levelOrder() {
//create a queue for the nodes
nodesQueue = new Queue<Node>();
nodesQueue.enqueue(root);
while(nodesQueue.size() > 0){
n = nodesQueue.dequeue();
//reached a leaf, nothing to do
if(n == null): continue
//process current node and enqueu its children
process(n.data);
enqueue(n.left);
enqueue(n.right);
}
The level-order traversal of the example tree above would be A B C D E
3 Binary Search Trees
3.1 Binary Search Trees
We've learned a lot of things about trees, but we haven't actually put any data in them yet. In a Binary Search Tree, we require that our data be sortable, and the rule is this: everything in the left subtree of a node is less than the node's data, and everything in the right subtree is greater. Pretty simple, right?
Here's some code to make that happen, if the tree is storing int's.
The insert() method adds an element to the tree, and find() returns a
boolean as to whether that element appears in the tree.
public class BSTofInts {
private class Node {
public Node left = null;
public Node right = null;
public int data;
public node(int d) {data = d; }
}
private Node root = null;
public boolean find(int element) {
return findFrom(root, item);
}
private boolean findFrom(Node n, int element) {
if (n == null) return false;
else if (element == n.data) return true;
else if (element < n.data))
return findFrom(m.left, element);
else
return findFrom(n.right, element);
}
public void insert(int element) {
root = insertBelow(root, element);
}
private Node insertBelow(Node n, int element) {
if (n == null)
return new Node(element);
if (element <= n.data)
n.left = insertBelow(n.left, element);
else
n.right = insertBelow(n.right, element);
return n;
}
}
3.2 Method Runtime
Note that we do not know the height of a BST, except to say that it is somewhere between \(O(log(n))\) and \(O(n)\), which is a massive range. The best we can say, is that both =find()=> and =insert()=> are \(O(h)\) where \(h\) is the height of the tree.
Credit: Gavin Taylor and Dan Roche for the original versions of these notes.