Unit 5: Process Management
Table of Contents
- 1. Unix Processes
- 2. Process Exiting
- 3. Process Creation and Management
- 4. The O.S. Scheduler
- 5. Process States
- 6. Pipelines and Process Groups
- 7. Programming with Process Groups
- 8. Process Groups and Terminal Signaling
- 9. Resource Duplication Across Forks
- 10. Inter-Process Communication and Pipes
- 11. Duplicating File Descriptor and Pipelines
1 Unix Processes
A process is an executing instance of a program. We have been discussing processes in one form or another throughout the class, but in this lesson we dive into the lifecycle of a process. How does a process get created? How is it managed? How does it die?
For starters, let's return to the definition of a process: an executing instance of a program. A program is the set of instructions for how a process operates when run, while a process is a current instance of that program as it executes. There can be multiple instances of the same program running; for example, multiple users can be logged into a computer at the same time, each running a shell, which is the same program with multiple executing instances.
A process is also an Operating System abstraction. It's a way to manage varied programs and contain them within individual units. It is via this abstraction that the O.S. can provide isolation, ensuring that one process cannot interfere with another. A process is also the core unit of the O.S. resource of Process Management which the main goal is to determine which process has access to the CPU and at what time.
In this lesson, we are going to trace the life and death of a Unix process, from the first nubile invocation to the final mortal termination. We'll begin at the end, with death, and work backwards towards birth. Throughout this lesson, we'll use the diagram below to explain these concepts. You can find a version of this diagram in APUE on page 201, Section 7.3.
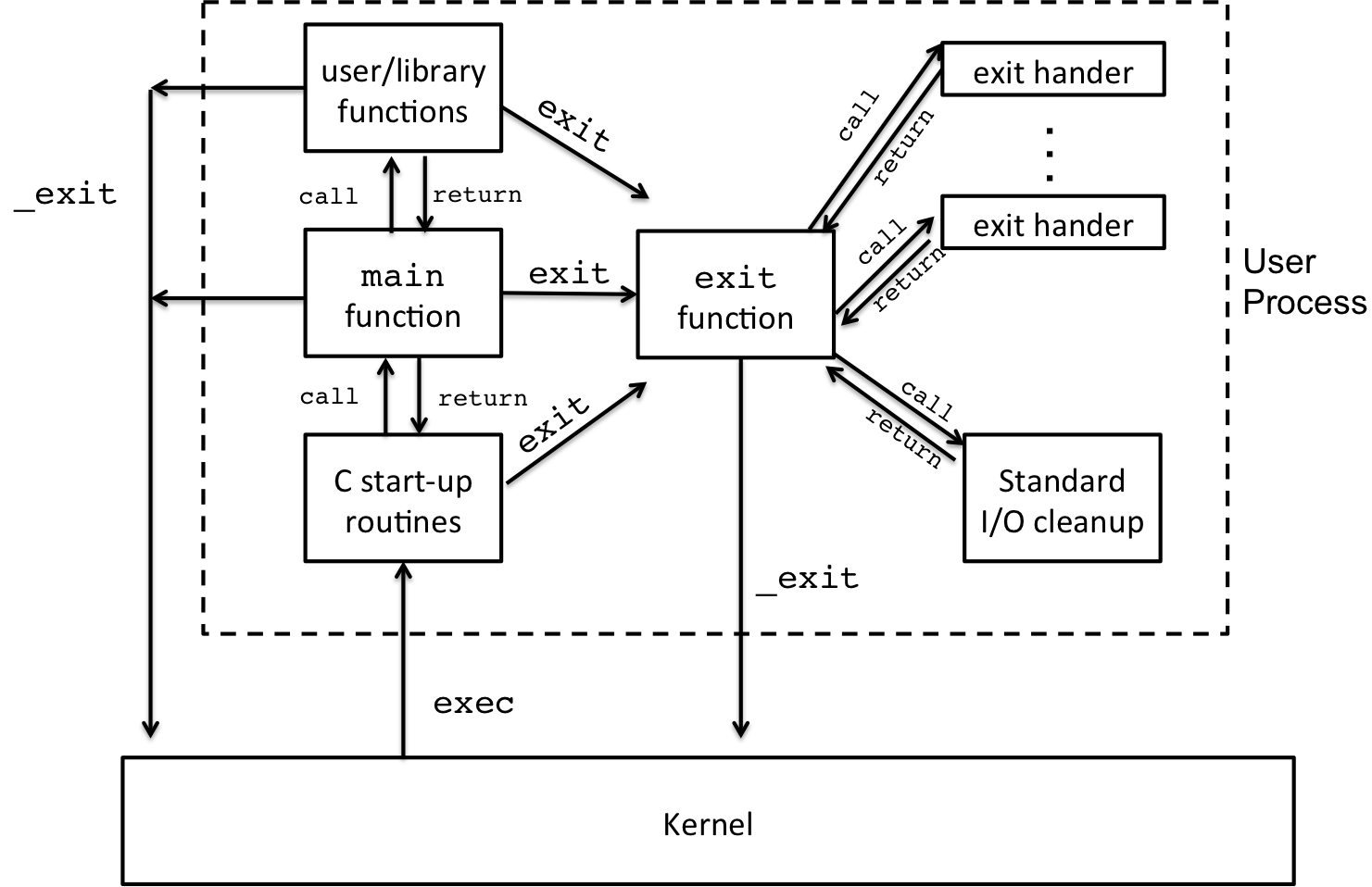
Figure 1: C Program Life Cycle: Invocation through Termination
2 Process Exiting
Let's start with a fairly simple question: How do we make a program
terminate in code? There are illogical ways to do this –
dereferencing NULL and forcing a segfault – but the standard
way to do this is to allow the main() function to return. What do
we do if want our program to logically terminate from another point
in the program, somewhere other than main()? We need a separate
mechanism to do that, and the solution is an exit call, like we did
in bash programming.
2.0.1 exit() and _exit() and _Exit()
There are three ways to forcefully exit a program:
_exit(): System calls that request the O.S. to terminate a process immediately without any additional code execution.exit(): C Standard Library exit procedure that will cleanly terminate a process by invoking additional code as requested by the user and to manage ongoing I/O._Exit(): C Standard Library exit procedure that will immediately terminate a process, essentially a wrapper to_exit()
To better understand these differences we can refer back to the diagram:
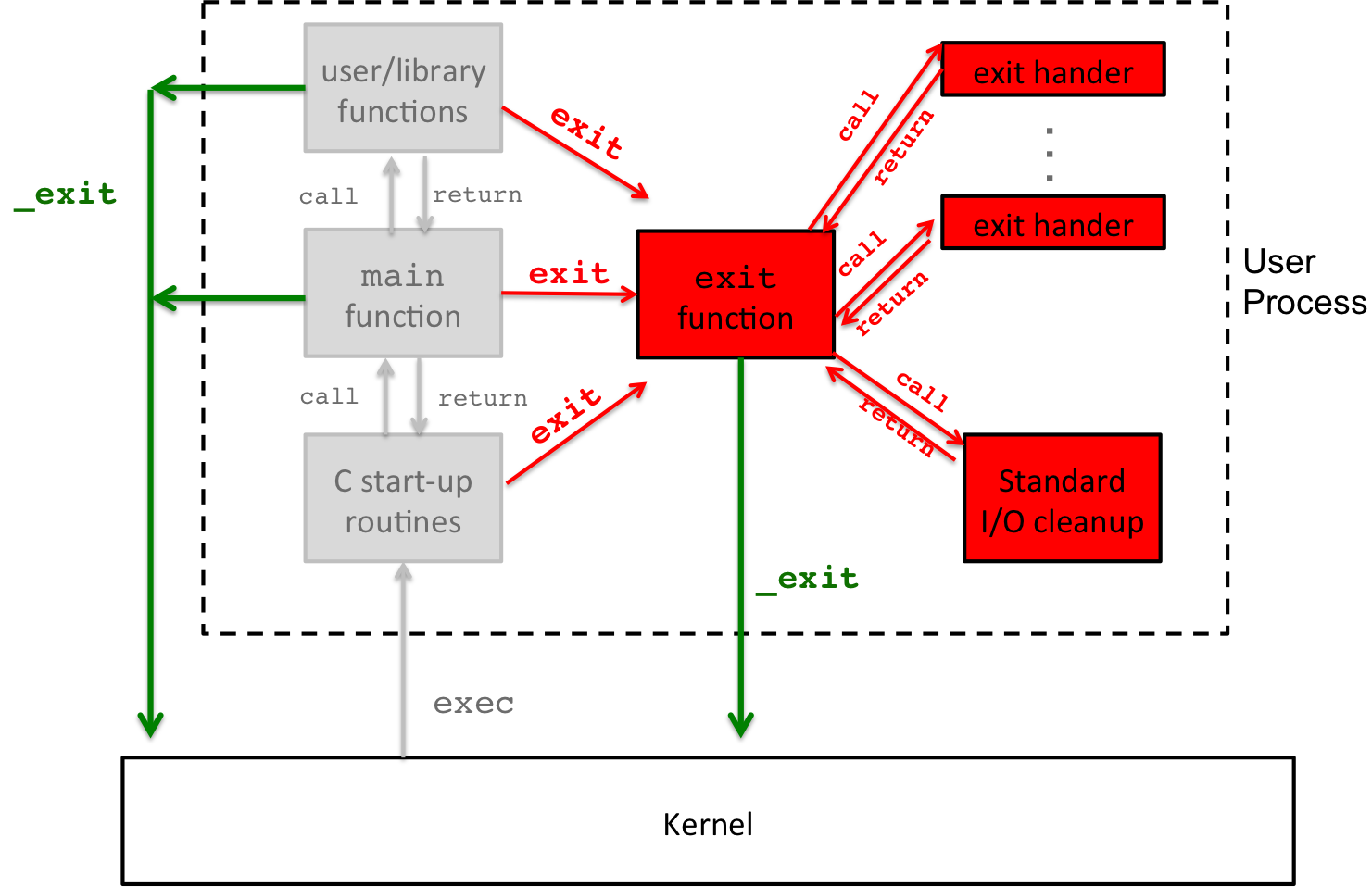
Figure 2: C Program Life Cycle: exit() vs. _exit()
The flow of the green arrows refer to the system call _exit()
which leads to direct termination of the process. Once a process is
terminated, the kernel is invoked to choose which process should run
next, which is why flow points towards the kernel. However, a call
to exit() (no underscore), at any point in the program execution,
starts a separate set of actions, which include running exit
handlers and I/O procedures. This is indicated in red in the
diagram, and eventually, once exit procedures are complete, exit()
calls _exit() to do the final termination. Not pictured is
_Exit(), which has the same action as _exit().
Like many of the O.S. procedures we've been discussing so far in this class, the exit procedure has both a system call version and a library call version. In general, when you program you will likely only use the library function, which is fine, but to be an effective programmer you need to understand the underlying O.S. procedures that enable the library routines.
2.0.2 I/O Buffering and Exit Procedures
One aspect of the standard library exit procedure is to handle I/O buffering that occurs within the C standard library. This depicted in the diagram like so:
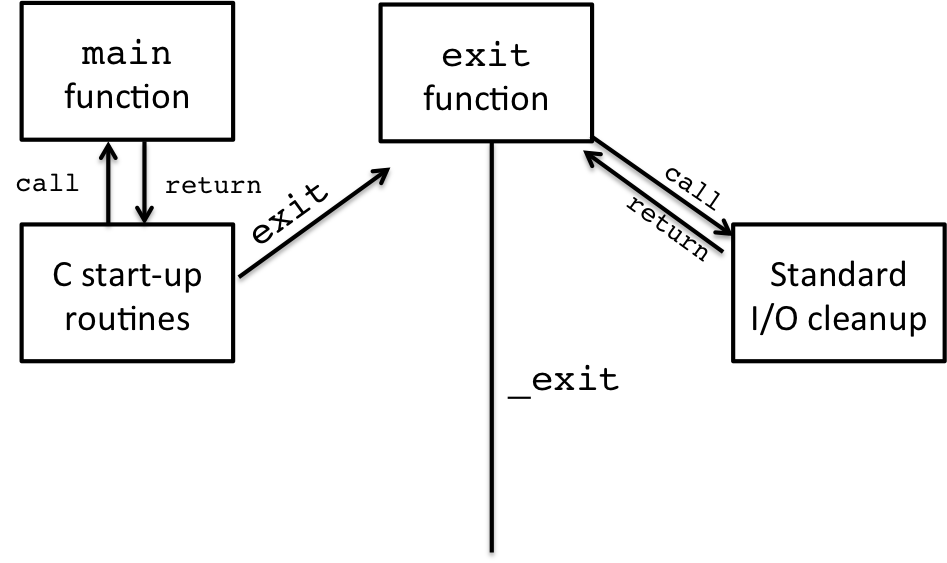
Figure 3: C Program Life Cycle: Standard I/O Cleanup
I/O bufferring in the C standard library is an attempt to limit the
number of system calls, i.e., calls to write(), which are
costly. A system call requires that the entire process be paused,
saved, and swapped out in favor of the OS, which then performs the
action, and once complete, the user process must be swapped back in
to complete its operation. Just enumerating all the steps of a
context switch is exhausting, and it is an expensive operation, one
that should be avoided except when absolutely necessary.
Buffering is one way to avoid excessive calls. When you call
printf() or another standard I/O library function that is printing
to the terminal or a file, the print does not occur right
away. Instead, it is buffered, or temporarily stored and waiting
to be completed. A print will become unbuffered whenever the buffer
is full, e.g., there is enough bytes to write and cannot store any
more, or when a line completes, as defined by printing a newline
symbol.
So if we were to look at the hello-world program:
int main(){
printf("Hello World!\n");
}
The printing of "Hello World!" includes a new line symbol, and thus the buffer is flushed and "Hello world!" is printed to the terminal. However, consider this version of the hello-world program:
int main(){
printf("Hello World!");
}
This time there is no newline, but "Hello World" is still printed to the terminal. How?
When the main() function returns, it actually returns to another
function within the C startup routines, which calls exit(). Then
exit() will perform a cleanup of standard I/O, flushing all the
buffered writes.
However, when you call _exit(), buffers are not cleared. The
process will exit immediately. You can see the difference between
these two procedures in these two programs:
/*exit_IO_demo.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(){
// I/O buffered since no newline
printf("Will print");
exit(0); //C standard exit
}
/*_exit_IO_demo.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(){
// I/O buffered since no newline
printf("Does not print");
_exit(0); //immediate exit!
}
You do not need to rely on the exit procedures to clear the I/O
buffers. Instead, you can directly flush the buffers with fflush()
library function. For example:
int main(){
// I/O buffered since no newline
printf("Will print once flushed");
fflush(stdout); // flushing stdout's buffer, printing
_exit(0); //immediate exit!
}
The fflush() function takes a FILE * and will read/write all
data that is currently being buffered. There is also an analogous
function, fpurge(), which will delete all data in the buffers.
2.0.3 Changing I/O Buffering policy
The buffering policy at the process level varies by input/output
mechanisms. For example, let's consider a program that prints to
stderr instead of stdout.
/*_exit_IO_stderr.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(){
// I/O not buffered for stderr
fprintf(stderr, "Will print b/c stderr is unbuffered");
_exit(0); //immediate exit!
}
In some ways, this is good policy. You want errors to be reported
immediately, not when it is most convenient for the buffer. There
is a side effect, however, writes to stderr are more expensive
since it requires an immediate context switch.
We can change the policy for how an input/output stream is
buffered. By default, stdout and stdin is line buffered which
means that input and output is buffered until a newline is
read/written. stderr is unbuffered, as described above. There
is also a third choice, fully buffered, which means writes/reads
occur once the buffer is full.
The library call to change the buffering policy is setvbuf(),
which has the following function declaration:
int setvbuf(FILE *stream, char *buf, int mode, size_t size);
You select which input/output stream is affected, such as stderr
or stdout, and you can also provide memory for the buffer with
its size. The mode option can have the following choices:
_IONBFunbuffered : data is written immediately to the device via the system callwrite()_IOLBFline buffered : data is written to the device usingwrite()once a newline is found or the buffer is full_IOFBFfully buffered : data is only written to the device usingwrite()once the buffer is full
In general, you do not need to specify a new buffer, instead just
want to affect the mode. For example, if we want to set stderr to
be line buffered, we can alter the program from above like so, and
the result would be that it would no longer print
/*_exit_IO_setvbuf.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(){
//stderr is now Line buffered
setvbuf(stderr, NULL, _IOLBF, 0);
// I/O now buffered for stderr
fprintf(stderr, "Will NOT print b/c stderr is now line buffered");
_exit(0); //immediate exit!
}
2.0.4 atexit() Exit Handlers
So far, we've seen within the context of I/O buffering, that the
exit() procedure will perform actions before executing the final
exit, with _exit(). What if you wanted to add an additional exit
processing? You do that with exit handlers.

Figure 4: C Program Life Cycle: exit handlers
Exit handers are functions that are automatically called whenever
a program is exit()'ing. You can register, in general, 32 exit
handlers using the atexit() library function. The order each exit
handler executes is in reverse order of their registration. Consider
the below program
/*exit_handler_demo.c*/
#include <stdio.h>
#include <stdlib.h>
void my_exit1(){
printf("FIRST Exit Handler\n");
}
void my_exit2(){
printf("SECOND Exit Handler\n");
}
int main(){
//exit handers execute in reverse order of registration
atexit(my_exit1);
atexit(my_exit2);
//my_exit2 will run before my_exit1
return; //implicitly calls exit()
}
The output of this program is:
#> ./exit_hander_demo SECOND Exit Handler FIRST Exit Handler
A couple of other things to note here is that the argument to
atexit() is a function. This is the first time we are using a
function pointer, or a reference to a function. We will do something
similar later in the class when setting up signal handlers, again
registering a function to be called when an event occurs.
2.0.5 Exit Statuses
The last bit of the exit() puzzle is exit status. Every program
exits with some status. This status can then be checked to learn
information about the execution of the process, for example, did
it exit successfully or on failure or error?
You can set the exit status of a program via the various exit()
calls:
_exit(int status);
exit(int status);
_Exit(int status);
Additionally, the return value of main() implicitly sets the exit
status. Convention indicates the following exit status:
- 0 : success
- 1 : failure
- 2 : error
We've seen this before when programming with bash scripting. Recall
that an if statement in bash executes a program:
if cmd #<--- executes command and checks exit status
then
else
fi
When cmd succeeds, i.e., returns with exit status 0, then the
then block is executed. If the cmd fails or there was an error,
the else block is executed. The special variable, $?, also
stores the exit status of the last executed program.
An exit status actually is more than just the argument to
_exit(). The kernel also prepares a termination status for a
process, one of those parts is the exit status. The termination
status also contains information about how the program
terminated, and we will concern ourselves more with termination status
when we discuss process management.
3 Process Creation and Management
3.1 The Birth of a Process
Now that we have good understanding about the death of a process, let's look at the birth of a process.
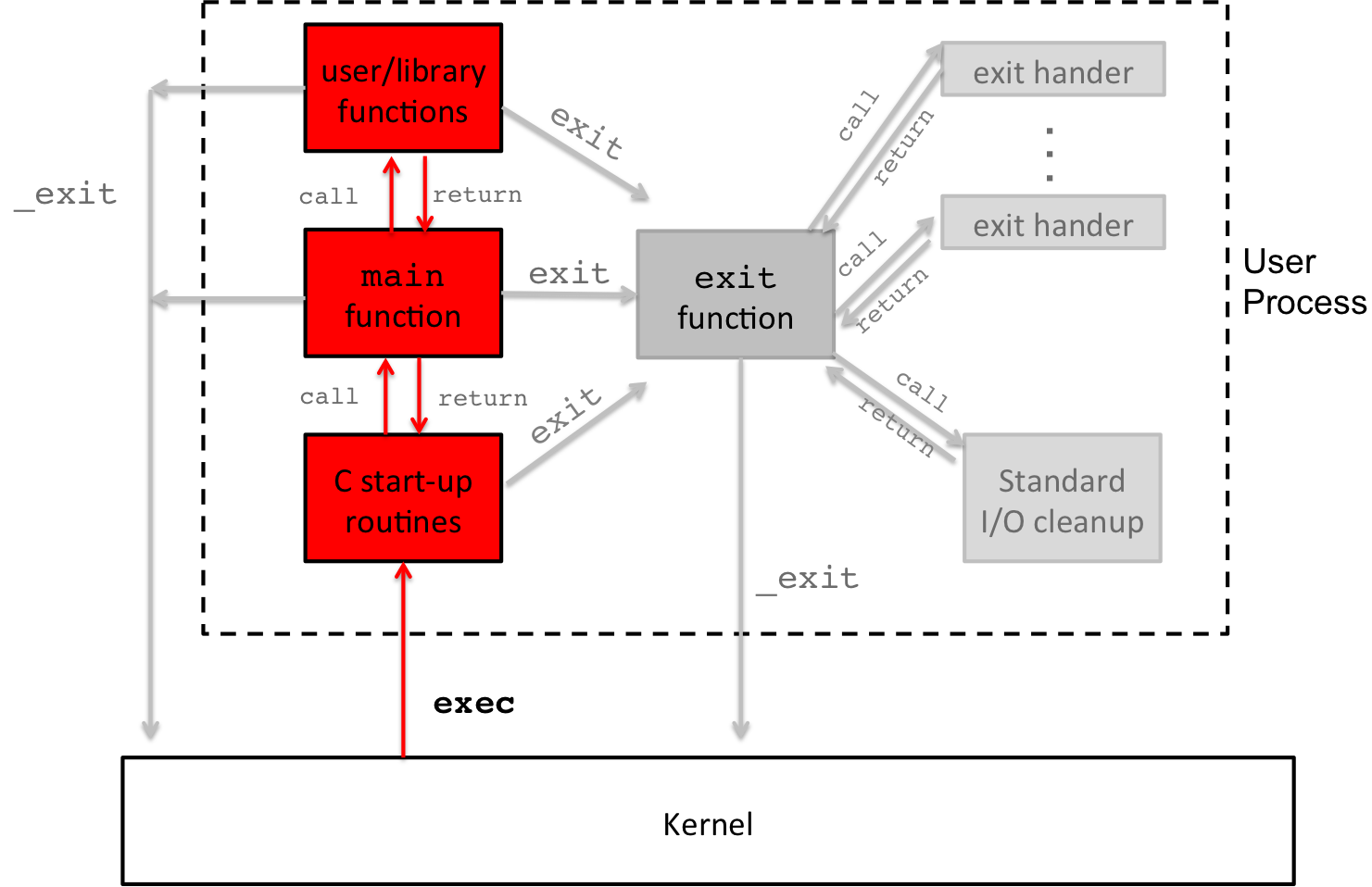
Figure 5: C Program Life Cycle: exec and startups
Forever, you have always learned that a program begins in main(),
but that's not exactly true. The part of the program you wrote
starts in main(), but, in fact, when you compile a program, there
is a set of additional functions that will execute first to set up
the environment. Once those complete, main() is called, and when
main() returns, it returns to those startup routines, which
eventually calls exit() … and we already know how that story
ends.
There is a more fundamental questions that we are not addressing:
How does a program actually load and execute as a process? This is
accomplished with the exec family of system calls, in particular
execv() and
3.2 Exec System Calls
The exec family of system calls simply loads a program from
memory and executes it, replacing the current program of the
process. Once the loading of instructions is complete, exec will
start execution through the startup procedures. We'll just discuss
the execv() system call, which has the following function
definition. Read the manual page to find the other forms of exec,
including execve() and execvp().
int execv(const char *path, char *const argv[]);
execv() takes a path to a program, as it lives within the file
system, as well as the arguments to that program. It's easier to
understand by looking at an example. The program below, will
execute ls.
/* exec_ls.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char * argv[]){
//arguments for ls
char * ls_args[2] = { "/bin/ls", NULL} ;
//execute ls
execv( ls_args[0], ls_args);
//only get here if exec failed
perror("execve failed");
return 2; //return error status
}
The execv() system call takes a path to the program, in this case
that is "/bin/ls", as well as an arg array. For this exec, the only
argument is the name of the program, ls_args[0]. You might notice
that the arguments to execv() match the arguments to main() with
respect to the argv array, and that's intentional. In some ways, you
can think of an exec calling the main() function of the program
directly with those arguments. You have to NULL the last argument so
that exec can count the total arguments, to set argc.
For example, we can extend this program to take an argument for ls
where it will long list the contents of the directory /bin. If we
were to call ls from the shell to perform this task, we would do so
like this:
ls -l /bin
We can translate that into an argv array with the following values:
//arguments for ls, will run: ls -l /bin
char * ls_args[4] = { "/bin/ls", "-l", "/bin", NULL} ;
// ^ ^ ^
// ' | |
// Now with an argument to ls -'------'
In this case, ls_argv has 3 fields set, not including NULL. We can
now pass this through to exec:
/*exec_ls_arg.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char * argv[]){
//arguments for ls, will run: ls -l /bin
char * ls_args[4] = { "/bin/ls", "-l", "/bin", NULL} ;
// ^ ^ ^
// ' | |
// Now with an argument to ls -'------'
//execute ls
execv( ls_args[0], ls_args);
//only get here if exec failed
perror("execve failed");
return 2; //return error status
}
Another thing to note is that upon success, an exec does not
return. Instead, the whole program is replaced with the exec'ed
program, when the exec'ed program returns, that's the final
return. To check if an exec fails, you don't need an if statement.
3.3 Forking Processes
So far, we've only loaded programs and executed them as an already
running process. This is not creating a new process, and for that we
need a new system call. The fork() system call will duplicate the
calling process and create a new process with a new process
identifier.
3.3.1 fork()
With the exception of two O.S. processes, the kernel and init process,
all process are spawned from another process. The procedure of
creating a new process is called forking: An exact copy of the
process, memory values and open resources, is produced. The original
process that forked, is called the parent, while the newly created,
duplicate process is called the child. Let's look at an example of a
process forking using the fork() system call:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(){
pid_t c_pid;
c_pid = fork(); //duplicate
if( c_pid == 0 ){
//child: The return of fork() is zero
printf("Child: I'm the child: %d\n", c_pid);
}else if (c_pid > 0){
//parent: The return of fork() is the process of id of the child
printf("Parent: I'm the parent: %d\n", c_pid);
}else{
//error: The return of fork() is negative
perror("fork failed");
_exit(2); //exit failure, hard
}
return 0; //success
}
The fork() system call is unlike any other function call you've seen
so far. It returns twice, once in the parent and once in child, and it
returns different values in the parent and the child.
To follow the logic, you first need to realize that once fork() is
called, the Operating System is creating a whole new process which is
an exact copy of the original process. At this point, fork() still
hasen't returned because the O.S. is context switched in, and now it
must return from fork() twice, once in the child process and once in
the parent, where execution in both process can continue.
3.3.2 Process identifiers or pid
Every process has a unique identifier, the process identifier or
pid. This value is assigned by the operating system when the process
is created and is a 2-byte number (or a short). There is a special
typedef for the process identifier, pid_t, which we will use.
In the above sample code, after the call to fork(), the parent's return value
from fork() is the process id of the newly created child
process. The child, however, has a return value of 0. On error,
fork(), returns -1. Then you should bail with _exit() because
something terrible happened.
One nice way to see a visual of the parent process relationship is
using the bash command pstree:
#> pstree -ah
init
├─NetworkManager
│ ├─dhclient -d -4 -sf /usr/lib/NetworkManager/nm-dhcp-client.action -pf /var/run/sendsigs.omit.d/network-manager.dhclient-eth0.pid -lf...
│ └─2*[{NetworkManager}]
├─accounts-daemon
│ └─{accounts-daemon}
(...)
At the top is the init process, which is the parent of all
proces. Somewhere down tree is my login shell
(...) ├─sshd -D │ └─sshd │ └─sshd │ └─bash │ ├─emacs get_exitstatus.c │ ├─emacs foursons.c │ ├─emacs Makefile │ ├─emacs get_exitstatus.c │ ├─emacs fork_exec_wait.c │ ├─emacs mail_reports.py │ └─pstree -ah (...)
And you can see that the process of getting to a bash shell via ssh
requires a number of forks and child process.
3.3.3 Retrieving Process Identifiers: getpid() and getppid()
With fork(), the parent can learn the process id of the child, but
the child doesn't know its own process id (or pid) after the fork
nor does it know its parents process id. For that matter, the parent
doesn't know its own process id either. There are two system calls to
retrieve this information:
//retrieve the current process id
pid_t getpid(void);
//retrieve the parent's process id
pid_t getppid(void);
There is no way for a process to directly retrieve its child pid
because any process may have multiple children. Instead, a process must
maintain that information directly through the values returned
from a fork(). Here is a sample program that prints the current
process id and the parent's process id.
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main(){
pid_t pid, ppid;
//get the process'es pid
pid = getpid();
//get the parrent of this process'es pid
ppid = getppid();
printf("My pid is: %d\n",pid);
printf("My parent's pid is %d\n", ppid);
return 0;
}
If we run this program a bunch of times, we will see output like this:
#> ./get_pid_ppid My pid is: 14307 My parent's pid is 13790 #> ./get_pid_ppid My pid is: 14308 My parent's pid is 13790 #> ./get_pid_ppid My pid is: 14309 My parent's pid is 13790
Every time the program runs, it has a different process id (or
pid). Every process must have a unique pid, and the O.S. applies a
policy for reusing process id's as processes terminate. But, the
parent's pid is the same. If you think for a second, this makes sense:
What's the parent of the program? The shell! We can see this by
echo'ing $$, which is special bash variable that stores the pid of
the shell:
#> echo $$ 13790
Whenever you execute a program on the shell, what's really going on is
the shell is forking, and the new child is exec'ing the new
program. One thing to consider, though, is that when a process forks,
the parent and the child continue executing in parallel: Why doesn't
the shell come back immediately and ask the user to enter a new
command? The shell instead waits for the child to finish process
before prompting again, and there is a system call called wait() to
just do that.
3.4 Waiting on a child with wait()
The wait() system call is used by a parent process to wait for the
status of the child to change. A status change can occur for a number
of reasons, the program stopped or continued, but we'll only concern
ourselves with the most common status change: the program terminated
or exited. (We will discuss stopped and continued in later lessons.)
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
Once the parent calls wait(), it will block until a child changes
state. In essence, it is waiting on its children to terminate. This is
described as a blocking function because it blocks and does not
continue until an event is complete.
Once it returns, wait() will returns the pid of the child process
that terminated (or -1 if the process has no children), and wait()
takes an integer pointer as an argument. At that memory address, it
will set the termination status of the child process. As mentioned
in the previous lesson, part of the termination status is the exit
status, but it also contains other information for how a program
terminated, like if it had a SEGFAULT.
3.4.1 Checking the Status of children
To learn about the exit status of a program we can use the macros from
sys/wait.h which check the termination status and return the exit
status. From the main page:
WIFEXITED(status)
returns true if the child terminated normally, that is,
by calling exit(3) or _exit(2), or by returning from main().
WEXITSTATUS(status)
returns the exit status of the child. This consists of the least significant
8 bits of the status argument that the child specified in a call to exit(3) or _exit(2) or as the
argument for a return statement in main().
This macro should only be employed if WIFEXITED returned true.
There are other checks of the termination status, and refer to the manual page for more detail. Below is some example code for checking the exit status of forked child. You can see that the child delays its exit by 2 seconds with a call to sleep.
/*get_exitstatus.c*/
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(){
pid_t c_pid, pid;
int status;
c_pid = fork(); //duplicate
if( c_pid == 0 ){
//child
pid = getpid();
printf("Child: %d: I'm the child\n", pid, c_pid);
printf("Child: sleeping for 2-seconds, then exiting with status 12\n");
//sleep for 2 seconds
sleep(2);
//exit with statys 12
exit(12);
}else if (c_pid > 0){
//parent
//waiting for child to terminate
pid = wait(&status);
if ( WIFEXITED(status) ){
printf("Parent: Child exited with status: %d\n", WEXITSTATUS(status));
}
}else{
//error: The return of fork() is negative
perror("fork failed");
_exit(2); //exit failure, hard
}
return 0; //success
}
3.5 Fork/Exec/Wait Cycle
We now have all the parts to write a program that will execute another program and wait for that program to finish. This reminds me of another program we've already used in this class… the shell, but you'll get to that later in the lab.
For now, consider the example code below which executes ls on the
/bin directory:
/*fork_exec_wait.c*/
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(int argc, char * argv[]){
//arguments for ls, will run: ls -l /bin
char * ls_args[3] = { "ls", "-l", NULL} ;
pid_t c_pid, pid;
int status;
c_pid = fork();
if (c_pid == 0){
/* CHILD */
printf("Child: executing ls\n");
//execute ls
execvp( ls_args[0], ls_args);
//only get here if exec failed
perror("execve failed");
}else if (c_pid > 0){
/* PARENT */
if( (pid = wait(&status)) < 0){
perror("wait");
_exit(1);
}
printf("Parent: finished\n");
}else{
perror("fork failed");
_exit(1);
}
return 0; //return success
}
And the execution:
aviv@saddleback: demo $ ./fork_exec_wait Child: executing ls total 5120 -rwxr-xr-x 2 root wheel 18480 Sep 9 18:44 [ -r-xr-xr-x 1 root wheel 628736 Sep 26 22:03 bash -rwxr-xr-x 1 root wheel 19552 Sep 9 18:57 cat -rwxr-xr-x 1 root wheel 30112 Sep 9 18:50 chmod -rwxr-xr-x 1 root wheel 24768 Sep 9 18:49 cp -rwxr-xr-x 2 root wheel 370096 Sep 9 18:40 csh -rwxr-xr-x 1 root wheel 24400 Sep 9 18:44 date -rwxr-xr-x 1 root wheel 27888 Sep 9 18:50 dd -rwxr-xr-x 1 root wheel 23472 Sep 9 18:49 df -r-xr-xr-x 1 root wheel 14176 Sep 9 19:27 domainname -rwxr-xr-x 1 root wheel 14048 Sep 9 18:44 echo -rwxr-xr-x 1 root wheel 49904 Sep 9 18:57 ed -rwxr-xr-x 1 root wheel 19008 Sep 9 18:44 expr -rwxr-xr-x 1 root wheel 14208 Sep 9 18:44 hostname -rwxr-xr-x 1 root wheel 14560 Sep 9 18:44 kill -r-xr-xr-x 1 root wheel 1394560 Sep 9 19:59 ksh -rwxr-xr-x 1 root wheel 77728 Sep 9 19:32 launchctl -rwxr-xr-x 2 root wheel 14944 Sep 9 18:49 link -rwxr-xr-x 2 root wheel 14944 Sep 9 18:49 ln -rwxr-xr-x 1 root wheel 34640 Sep 9 18:49 ls -rwxr-xr-x 1 root wheel 14512 Sep 9 18:50 mkdir -rwxr-xr-x 1 root wheel 20160 Sep 9 18:49 mv -rwxr-xr-x 1 root wheel 106816 Sep 9 18:49 pax -rwsr-xr-x 1 root wheel 46688 Sep 9 18:59 ps -rwxr-xr-x 1 root wheel 14208 Sep 9 18:44 pwd -r-sr-xr-x 1 root wheel 25216 Sep 9 19:27 rcp -rwxr-xr-x 2 root wheel 19760 Sep 9 18:49 rm -rwxr-xr-x 1 root wheel 14080 Sep 9 18:49 rmdir -r-xr-xr-x 1 root wheel 628800 Sep 26 22:03 sh -rwxr-xr-x 1 root wheel 14016 Sep 9 18:44 sleep -rwxr-xr-x 1 root wheel 28064 Sep 9 18:59 stty -rwxr-xr-x 1 root wheel 34224 Sep 9 21:59 sync -rwxr-xr-x 2 root wheel 370096 Sep 9 18:40 tcsh -rwxr-xr-x 2 root wheel 18480 Sep 9 18:44 test -rwxr-xr-x 2 root wheel 19760 Sep 9 18:49 unlink -rwxr-xr-x 1 root wheel 14112 Sep 9 19:32 wait4path -rwxr-xr-x 1 root wheel 551232 Sep 9 19:19 zsh Parent: finished
The parent first forks a child process. In the child process, the
execution is replaced by ls which prints the output. Meanwhile, the
parent wait's for the execution to complete before continuing.
Imagine now this process occurring in a loop, and instead of running
ls, the user provides the program that should run. That's a shell,
and that's what you will be doing in the next lab.
4 The O.S. Scheduler
The scheduler of the O.S. is the most fundamental and perhaps the most important component of the O.S. kernel. Its sole task is to decide which process will run next on the CPU, the heart of process management. This decisions cannot be made lightly. There are many contingent properties to consider when discussing the scheduler and process management; such as, ensuring that all process have a chance to run and that the cpu is being fully utilized.
To complicate the issue, not all process are ready to run. Process can be in many different states. Some are ready and can be run immediately, for sure, but others may be blocked or waiting for some other process to complete, like a shell, or for a hardware component to become available, like reading from disc. Some process are neither blocked nor waiting, but just sitting around wasting resources … zombies, and others loose their parents and are orphaned and adopted by other processes. It's a whole ecosystem.
We will begin the discussion by first overviewing a few different scheduling concepts. Next, we'll explore the Unix scheduling routine, and how you, the programmer, can interact with the schedule to change the priority of your processes.
4.1 O.S. Scheduling Ideas
A good scheduling algorithm must meet the following constraints:
- CPU Utilization: The processor should be utilized at the highest possible level. If there exists a process that can run, it should be running.
- Turnaround Time: How long does it take for a process to run once it is ready to run?
- Fairness: All tasks, of equal priority, should have the same opportunity to run. Or, no process should be starved for resources, and unable to run.
Based on these concepts, we can come up with some fairly naive strategy for scheduling. Consider a situation where, you — the processor — are being tasked with completing some amount of work divided into jobs. Jobs arrive in some order, each takes some amount of time, and once you start a job, you don't stop until you finish it.
One strategy you could employ is just First-Come-First-Serve, like a queue. While this is effective at CPU Utilization and Fairness, it doesn't have good turnaround. A job at the end of the queue could end up waiting a long time before it actually gets to run, and that job could be the computation needed most of all.
Another strategy, we could employ is some kind of introspection scheduling routine. Suppose we knew how long it would take for a job to complete, then we could just always schedule the shortest job next. Or, perhaps we are facing a deadline, like we must compute a flight trajectory RIGHT NOW or this plane is going down, then we could schedule jobs based on a deadline, or deadline scheduling. These strategies work great if we know how long tasks take to complete; we do not have that luxury on most Unix systems — have you ever written an infinite loop?
4.2 Preemptive Scheduling
Unix systems, and most modern consumer Operatin Systems, use a form of preemptive scheduling, which means that a process gets scheduled for some amount of time, then it is preempted before it get's to finish and another process get's to run for some amount of time, which will get preempted, allowing another process to run, and so on. Returning to the scenario where you are the scheduler, now you don't have to fully complete the job before moving onto the next. We can again come up with a few reasonable strategies for how to schedule tasks.
One simple solution to scheduling is to just allow each task to run for a set amount of time, say 500 milliseconds, and then you swap it out with the next job, running for 500 milliseconds, and then the next, and etc. You move in this round robin fashion until all the jobs are complete, and, on its surface, this seems like a great strategy. The CPU is being utilized a lot, all jobs have the same turnaround, and it is the most fair way to divide time as possible.
But, there are other factors to consider. Maybe if you let a job run for a bit longer then your timeout, it would have completed, and would not have to rotate all the way around before finishing? Or, maybe a job is using the CPU but it is not doing any computation; instead, it is just waiting for the disc to return with data, which can take an eternity in CPU time. It doesn't seem like the CPU is being properly utilized in either of those situations.
4.3 Priority Queue Scheduling
Unix implements a hybrid strategy for scheduling that is a mix of round-robin scheduling and priority scheduling, where higher priority process go first. Essentially, there is a set of priority queues, from -20 to positive 19, and within each priority queue, process are run in a round robin fashion, but which queue executes is chosen based on priority preference. To avoid starvation, process can be moved from lower priority queues to higher priority queues when they have not run in awhile. This strategy is called multilevel queue scheduling and it is used in most Unix systems, and is very effective and highly efficient in the selection of next processes to run. It is also easily customized and adaptable for user needs, e.g., running tasks at the highest priority.
The gritty details of the Unix scheduler is a topic for your Operating Systems class, not systems programming, and instead we will concern ourselves with how we interact with the scheduler. There are two key questions to address:
- Given a process, how do we understand its priority?
- And, how do we change its priority?
4.4 How nice a program is its priority
In Unix, the concept of priority is described as how nice a process is to another process. The nicer a process is, the more willing it is for another process to run in its stead. Thus, nicer processes have lower priority and meaner processes have higher priority.
The nice-ness scale is between -20, very mean, to 19, very nice. By default, all programs are born with niceness 0: just plain ambivalent. Some programs must then become less nice, such as interactive process that must meet some deadline. For example, you want your computer to play sound when you click on something, or, for that matter, your mouse to move when you move it. Those process shouldn't be scheduled with a low priority because it would degrade the user experience.
There are also other process running where being nice is fine. For example, many daemons, programs constantly running the background, do not need a lot of priority. They are not interactive, and not being scheduled right away is not going to upset any users.
4.5 Viewing Process State with ps
One way to view the nice level of a process is using the shell
command ps, short for process state. The ps command is an
amazing tool for inspecting the state of process, and below, we
use it to show the nice-ness of the process running on a typical
Linux system in the lab.
#> ps axo nice,comm,pid --sort nice NI COMMAND PID -20 cpuset 36 -20 khelper 37 -20 netns 39 -20 kintegrityd 43 -20 kblockd 44 -20 ata_sff 45 -20 md 47 -20 crypto 56 -20 kthrotld 65 -20 binder 69 -20 deferwq 88 -20 charger_manager 89 -20 devfreq_wq 90 -20 ext4-dio-unwrit 282 -20 rpciod 448 -20 nfsiod 455 -20 kpsmoused 549 -20 kvm-irqfd-clean 887 -20 iprt 1224 -20 hd-audio0 1353 -11 pulseaudio 1735 -10 krfcommd 639 0 init 1 (...)
These commands, with negative nice values, are vital to the
execution of the computer. For example, cpuset is a process that
assists with loading of memory and process for execution, the
pulseaudio systems is used for audio output, and the various
k* commands are kernel process. Those really need to be run with
high priority.
In the middle, you'll find many process with priority 0.
(...) 0 ntpd 2040 0 sshd 13782 0 sshd 13789 0 bash 13790 0 emacs 14453 0 emacs 14712 0 emacs 15219 0 emacs 15273 0 emacs 15304 0 emacs 18917 0 kworker/7:0 21860 0 emacs 27417 0 crontab 28380 0 sh 28381 0 sensible-editor 28382 0 emacs23 28390 0 sshd 29814 0 sshd 29821 0 bash 29822 0 crontab 29894 0 sh 29895 (...)
These process are user-level process. I have a number of emacs
sessions open, which all have equal priority. The shell, bash, is
also running with priority 0. Finally, at the bottom, are the nicest
of processes:
(...) 1 rtkit-daemon 1737 5 ksmd 52 19 khugepaged 53
The rtkit-daemon is a process for realtime scheduling, but it
doesn't need to run that often, in relation to the process it is
scheduling. Thus, its just a bit nice. While khugepaged is a process
that manages large memory pages, collapsing them whenever necessary,
but this operation doesn't have to occur for the system to function
properly, it's just nice when it does. Thus, the priority of this
process is quite low, being very nice.
4.6 Programming Priority with getpriority() and nice()
When programming, we can inspect the current priority level of a
process using the getpriority() system call, which has the
following function declaration:
#include <sys/time.h>
#include <sys/resource.h>
int getpriority(int which, int who);
The which is for which kind of priority we are interested in. The
Unix system has multiple priority indicators, but we are only
concerned with the process level priority, or PRIO_PROCESS. The
who is to query the priority of a given process (or other identity)
by id. Using the value 0 for who refers to the current process.
Here's a program that will print the current nice value for the process:
/*getpriority.c*/
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/resource.h>
int main(){
int prio;
prio = getpriority(PRIO_PROCESS, 0); //get the priority of this process
printf("Priority: %d\n",prio);
return 0;
}
Of course, since the default priority of any process is 0, the output of this program is:
#> ./getpriority Priority: 0
We can change the priority of a process using the nice command,
which exists as both a command line tool and system call. It's
purpose is to make programs more nice or less nice. For example,
on the command line, we can run the getpriority with a nice value
of 10.
#> nice -n 10 ./getpriority Priority: 10
The output now indicates that the priority of the program is 10; it
is more nice, more willing to let other programs with lower priority
values run. We can try and set a negative priority value with
nice:
#>nice -n -10 ./getpriority nice: setpriority: Permission denied Priority: 0
This will fail because only the privileged user can set a
negative nice value; however, sudo can make this sandwich.
#> sudo nice -n -10 ./getpriority Password: Priority: -10
The sudo command says, run this command as the privilege super user
… you do not have sudo privilege on the lab machines.
In code, we can do the same thing using the nice() system call:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/resource.h>
int main(){
int prio;
prio = getpriority(PRIO_PROCESS, 0); //get the priority of this process
printf("Priority: %d\n",prio);
if( nice(10) != 10){ //error checking is different
perror("nice");
return 1;
}
prio = getpriority(PRIO_PROCESS, 0); //get the priority of this process
printf("Priority: %d\n",prio);
return 0;
}
One thing to note about nice() is that it returns the new priority
value, which may be negative. To error check, you must compare the
output of nice() with the value you expect.
5 Process States
Now that we have a decent understanding about how process are scheduled and how to interact with the O.S. to affect the priority of scheduling, let us turn our attention to the different states of a process. This is an important discussion because a scheduler must consider both the priority of a process and if it ready to run in order to maximize the utilization of the CPU. It turns out that not all processes are ready to run, and that a process can be in a number of different states.
5.1 Running, Waiting, Blocked, and Undead
There are three main states of a process. It may be running, which means it is currently running on the CPU; it may be ready and waiting, which menas that it is ready to run immediately if selected; and, it may be blocked and waiting, which means that it is not ready to run because some other information is needed by the process before it can proceed. A scheduler will consider both the priority of the process as well as it's current state
A process can be blocked for a number of reasons. Perhaps the most common cause of a process being blocked is I/O, such as reading and writing from a device. Consider that a read/write is a system call, which means that a context switch must occur where the process stops running and the kernel starts running to complete the action. Conceptually, we'd like to think that the context switch occurs immediately, the process swaps out, the kernel swaps in, performs the action, and the kernel swaps out, and the process swaps back in and continues on — but it doesn't work that way.
Instead, once the system call is initiated, the process is blocked and waiting for the system call to complete. At this point, the process is no longer eligible to be run, i.e., it is not ready, and the scheduler can schedule another process to run. The next process may be the kernel, which could complete the system call and return the result and unblock the process, or it could just be another user process, in which case the blocked process remains so.
Another way to think about how I/O blocks a process is to consider
the shell. The shell prompts a user for input by reading from
stdin, but it cannot continue until the user actually typed
something into the terminal and hits "enter." That could take an
eternity in compute cycles, and instead, the shell is blocking
on I/O waiting for user input. In the meanwhile, other processes
can run, and this is how the scheduler ensures high utilization.
Beyond I/O, a process can block for other reasons. For example, a
call to wait() is a blocking system call. The parent process is
designated to block and will not proceed until the kernel
recognizes a state change in the child, which will unblock the
parent.
5.2 Undead processes: Zombies
To understand the idea behind undead process, you must first think
about how the system call wait() functions. When a parent is
calling wait() it is specifically blocking until the child
process has terminated (or changed state). That means, there is
some period of time between when the process actually terminates
and when the parent process becomes unblocked. The child process
still exists during that short window, but is not alive … it is
undead, or a zombie!
A zombie is a process that has terminated but has not been
wait()'ed on by its parent. For example, consider the following
program:
/*zombies.c*/
int main(){
int i;
for(i=0; i<10;i++){
if(fork() == 0){ //create a child
_exit(0); // and exit
}
}
while(1); //run forever
}
The parent process will fork 10 children, who all just _exit()
immediately, but the parent does not call wait() and instead
spin's in a while loop. The child processes have terminated and are
now in limbo, not running but waiting to be wait()'ed on by the
parent. They are zombies! And we can see this state by looking at
the ps output:
#> ps -o pid,comm,state PID COMMAND STATE 2362 bash S 2463 zombies R 2464 zombi <defunct> Z 2465 zombi <defunct> Z 2466 zombi <defunct> Z 2467 zombi <defunct> Z 2468 zombi <defunct> Z 2469 zombi <defunct> Z 2470 zombi <defunct> Z 2471 zombi <defunct> Z 2472 zombi <defunct> Z 2473 zombi <defunct> Z 2475 ps R
"Z" is for Zombie, while "R" is for running. The additional "<defunct>" indicator is what the UNIX system uses to indicate that the process is now a zombie.
The big problem with zombie processes is in long running services. If you have zombie leak, these process can stick around for the entirety of the parent program. This wastes resources, and eventually, a zombie apocalypse will occur, and you're kernel will crash as it slowly runs out of resources.
5.3 Orphan Process, init, and daemons
At this point you may be wondering, what happens if the parent dies
before the children? Won't the children become zombies forever if
there is no parent to ever call wait()?
The answer is no. If a parent dies before the children, those
children are now designated as orphans. The special process
init inherits all orphans and will call wait() on them once
the children complete.
It is sometimes desirable for a process to become an orphan and be
inherited by init, such as long running process that always
execute in the background. In Unix terms, such process are called
daemons, and if you look at all the processes running on your
unix computer, these are processes with names that end in "d." A
daemon is usually formed by having a process fork a child, which
executes the logic of the daemon, while the parent dies. The daemon
is now an orphan, which is inherited by init, and the daemon
continues running happily in the background.
6 Pipelines and Process Groups
In the last lesson and lab, we've been discussing job control and
the mechanisms that enable it. Generally, job control is a feature
of the shell and supported by the terminal device driver. The shell
manages which jobs are stopped or running and notifies the terminal
driver which job is currently in the foreground. The terminal device
driver listens for special keys, like Ctrl-c or Ctrl-z, and
delivers the appropriate signal to the foreground process, like
terminate or stop.
That narrative is fairly straightforward, as long as there is only one process running within a job, but a job may contain more than one process, which could complicate the actions of the terminal device driver. Additionally, jobs can be further grouped together into sessions, and the mechanisms that enable all this interaction requires further discussion. In this lesson, we will explore process grouping and how this operating system services support job control and shell features we've grown to rely on (and love?).
6.1 Pipeline of processes
Consider the following pipeline:
sleep 10 | sleep 20 | sleep 30 | sleep 50 &
Here we have four different sleep commands running in a
pipeline. The sleep command doesn't read or write to the terminal;
it just sleeps for that many seconds and then exits. None of the
sleep commands are blocking or waiting on input from another sleep
command, so they can all run independently. We just happend to put
them in a pipeline, but what is the impact of that? How long will
this job take to complete?
One possibility is that each sleep command will run in
sequence. First sleep 10 runs, then sleep 20, then sleep 30
runs, and finally sleep 50 runs, and thus it would take
10+20+30+50 = 110 seconds for the pipeline to finish. Another
possibility is that they run all at the same time, or concurrently
or in parallel, in which case the job would complete when the
loggest sleep finishes, 50 seconds.
These two possibilities, in sequence and in parallel, also describe two possibilities for how a pipeline is executed. In sequence would imply that the shell forks the first item in the pipeline, lets that run, then the second item in the pipeline, lets that run, and so on. Or, in parallel: the shell forks all the items in the pipeline at once and lets the run concurrently. The major difference between these two choices is that a pipeline executing in sequence would have a single process running at a time for each total job while executing in parallel, however, would have multiple currently running processes per job.
By now, hopefully, you've already plugged that pipeline into the
shell and found out that, yes, the pipeline executes in parallel,
not in sequence. We can see this as well using the ps command.
sleep 10 | sleep 20 | sleep 30 | sleep 50 & [1] 4128 aviv@saddleback: ~ $ ps -o pid,args PID COMMAND 3981 -bash 4125 sleep 10 4126 sleep 20 4127 sleep 30 4128 sleep 50 4129 ps -o pid,args
6.2 Process Grouping for Jobs
The implication of this discovery, that all process in the pipeline run concurrently, is that the shell must use a procedure for forking each of the process individually. But, then, how are these process linked? They are suppose to be a single job after all, and we also know that the terminal device driver is responsible for delivering signals to the foreground job. There must be some underlying procedure and process to enable this behavior, and, of course, there is.
The operating system provides a number of ways to group processes together. Process can be grouped into both process groups and sessions. A process group is a way to group processes into distinct jobs that are linked, and a session is way to link process groups under a single interruptive unit, like the terminal.
The key to understanding how the pipeline functions is that all of
these process are places in the same process group, and we can see
that by running the pipeline again. This time, however, we can also
request that ps outputs the parent pid (ppid) and the process
group (pgid) in addition to the process id (pid) and the command
arguments (args).
#> sleep 10 | sleep 20 | sleep 30 | sleep 50 & [1] 4134 #> ps -o pid,pgid,ppid,args PID PGID PPID COMMAND 3981 3981 3980 -bash 4131 4131 3981 sleep 10 4132 4131 3981 sleep 20 4133 4131 3981 sleep 30 4134 4131 3981 sleep 50 4135 4135 3981 ps -o pid,pgid,ppid,args
Notice first that the shell, bash, has a pid of 3981 and process
group id (pgid) that is the same. The shell is in it's own process
group. Similarly, the ps command itself also has a pid that is the
same as its process group. However, the sleep commands, are in the
process group id of 4131, which also is the pid of the first process
in the pipeline. We can visualize this relationship like so:
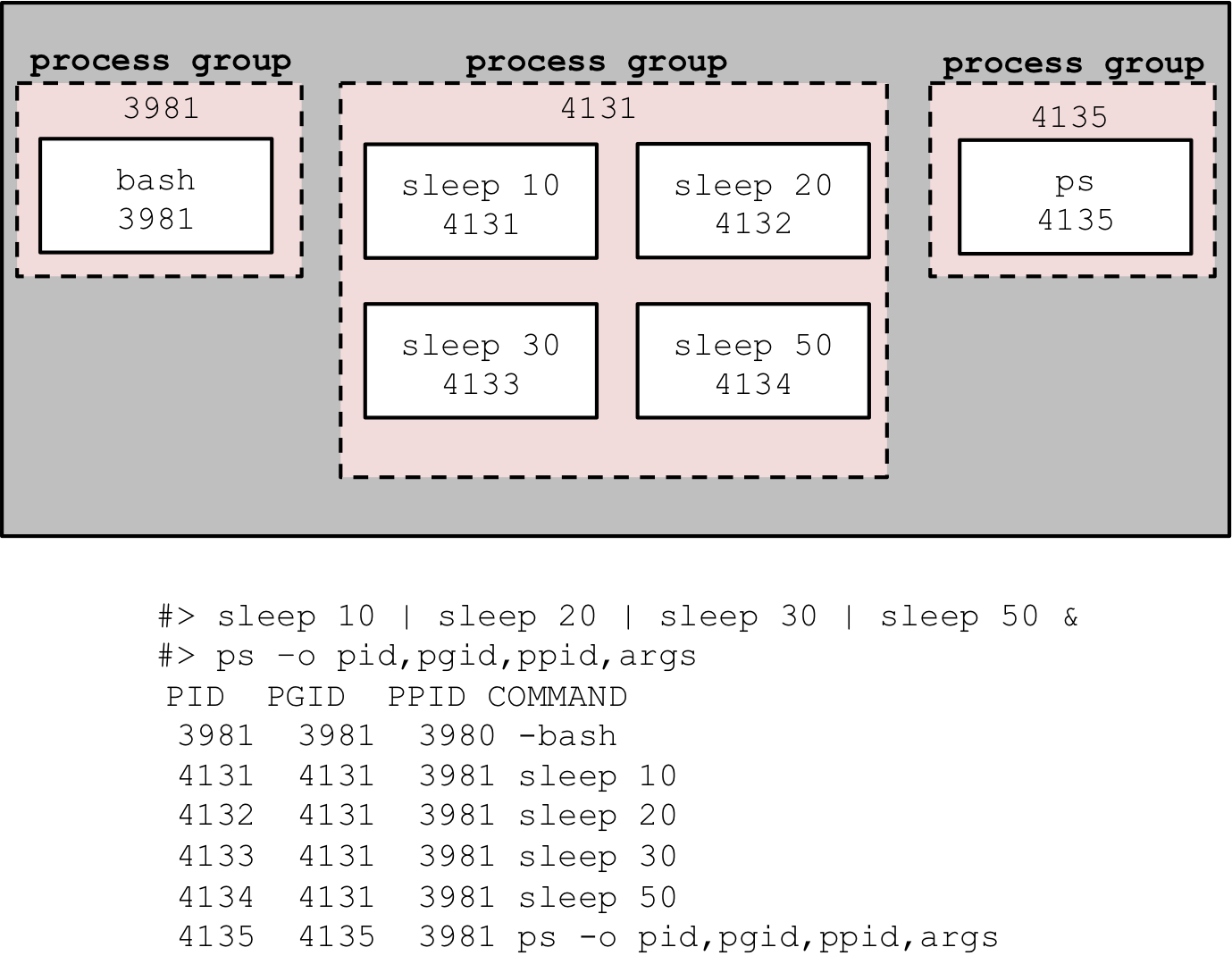
Figure 6: Processes grouping in pipelines
As you can see, the rule of thumb for process grouping is that process executing as the same job, e.g., a single input to the shell as a pipeline, are placed in the same group. Also, the choice of process group id is the pid of the process.
7 Programming with Process Groups
Below, we will look at how we program with process groups using system calls, and we will investigate this from the perspective of the programmer as well as how the shell automatically groups process. We will use series of fairly straight forward system calls, and to bootstrap that discussion, we outline them below with brief descriptions.
Retrieving pid's or pgid's:
pid_t getpid(): get the process id for the calling processpid_t getppid(): get the process id of the parent of the calling procespid_t getpgrp(): get the prcesso group id of the calling processpid_t getpgid(pid_t pid): get the process group id for the proces identified by pid
Setting pgid's:
pid_t setpgrp(): set the process group of the calling process to iteself, i.e. after a call tosetpgr(), the following condition holds getpid() == getpgrp().pid_t setpgid(pid_t pid, pid_t pgid): set the process group id of the process identified bypidto thepgid, ifpidis 0, then set the process group id of the calling process, and ifpgidis 0, then the pid of the process identified bypidand is made the same as its process group, i.e.,setpgid(0,0)is equivalent to callingsetpgrp().
7.1 Retrieving the Process Group
Each process group has a unique process group identifier, or pgid,
which are typically a pid of a process that is a member of the
group. Upon a fork(), the child process inherits the parent's
process group. We can see how this works with a small program that
forks a child and prints the proces group identifies of both parent
and child.
int main(int argc, char * argv[]){
/*inherit_pgid.c*/
pid_t c_pid,pgid,pid;
c_pid = fork();
if(c_pid == 0){
/* CHILD */
pgid = getpgrp();
pid = getpid();
printf("Child: pid: %d pgid: *%d*\n", pid, pgid);
}else if (c_pid > 0){
/* PARRENT */
pgid = getpgrp();
pid = getpid();
printf("Parent: pid: %d pgid: *%d*\n", pid, pgid);
}else{
/* ERROR */
perror(argv[0]);
_exit(1);
}
return 0;
}
Here is the output of running this program.
#> ./inherit_pgid Parent: pid: 3630 pgid: *3630* Child: pid: 3631 pgid: *3630*
Notice that the process groups are the same, and that's because a child inherits the process group of its parent. Now let's look at a similar program that doesn't fork, and instead just prints the process group identifier of itself and its parent, which is the shell.
/*getpgrp.c*/
int main(int argc, char * argv[]){
pid_t pid, pgid; //process id and process group for this program
pid_t ppid, ppgid; //process id and proces group for the _parent_
//current
pid = getpid();
pgid = getpgrp();
//parent
ppid = getppid();
ppgid = getpgid(ppid);
//print this parent's process pid and pgid
printf("%s: (current) pid:%d pgid:%d\n", argv[0], pid, pgid);
printf("%s: (parrent) ppid:%d pgid:%d\n", argv[0], ppid, ppgid);
return 0;
}
If we were to run this program in the shell, you might expect that both the child and the parent would print the same process group. Of course, why shouldn't this be the case? The program is a result of a fork from the shell, and thus the parent is the shell and the child is the program, and that's what just happened before, the parent and child had the same process group. But, looking at the output, that is not what occurs here.
#> ./getpgrp ./getpgrp: (current) pid:3760 pgid:3760 ./getpgrp: (parrent) ppid:369 pgid:369
Instead, we find that the parent, which is the shell, is not in the
same process group as the child, the getpgrp program. Why is that?
This is because the new process is also a job in the shell and each
job needs to run in its own process group for the purpose of terminal
signaling. What we can now recognize from these examples, starting
with the pipeline of sleep commands, is that a shell will fork each
process separately in a job and assign the process group id based on
the first child forked, as is clear upon further inspection of the
output of these two examples:
#> sleep 10 | sleep 20 | sleep 30 | sleep 50 & [1] 4134 #> ps -o pid,pgid,ppid,args PID PGID PPID COMMAND 3981 3981 3980 -bash 4131 4131 3981 sleep 10 4132 4131 3981 sleep 20 4133 4131 3981 sleep 30 4134 4131 3981 sleep 50 4135 4135 3981 ps -o pid,pgid,ppid,args
#> ./inherit_pgid Parent: pid: 3630 pgid: *3630* Child: pid: 3631 pgid: *3630*
7.2 Setting the Process Group
Finally, now that we have learned to identify the process group,
the next thing to do is to assign new process groups. There are two
functions that do this: setpgrp() and setpgid().
setpgrp(): sets the process group of the calling process to itself. That is the calling process joins a process group of one, containing itself, where its pid is the as its pgid.setpgid(pid_t pid, pid_t pgid): set the process group of the process identified bypidtopgid. Ifpidis 0, then sets the process group of the calling process topgid. Ifpgidis 0, then sets the process group of the process identified bypidtopid. Thus,setgpid(0,0)is the same assetpgid().
Let's consider a small program that sets the process group of the
child after a fork using setpgrp() call from the child. The
program below will print the process id's and process groups from
the child's and parent's perspective.
/*setpgrp.c*/
int main(int argc, char * argv[]){
pid_t cpid, pid, pgid, cpgid; //process id's and process groups
cpid = fork();
if( cpid == 0 ){
/* CHILD */
//set process group to itself
setpgrp();
//print the pid, and pgid of child from child
pid = getpid();
pgid = getpgrp();
printf("Child: pid:%d pgid:*%d*\n", pid, pgid);
}else if( cpid > 0 ){
/* PARRENT */
//print the pid, and pgid of parent
pid = getpid();
pgid = getpgrp();
printf("Parent: pid:%d pgid: %d \n", pid, pgid);
//print the pid, and pgid of child from parent
cpgid = getpgid(cpid);
printf("Parent: Child's pid:%d pgid:*%d*\n", cpid, cpgid);
}else{
/*ERROR*/
perror("fork");
_exit(1);
}
return 0;
}
And, here's the output:
#> ./setpgrp Parent: pid:20178 pgid: 20178 Parent: Child's pid:20179 pgid:*20178* Child: pid:20179 pgid:*20179*
Clearly, something is not right. The child sees a different pgid is different than the parent. What we have here is a race condition, which is when you have two processes running in parallel, you don't know which is going to finish the race first.
Consider that there are two possibility for how the above program will execute following the fork. In one possibility, after the fork, the child runs before the parent and the process group is set properly, and in the other scenario, the parent runs first reads the process group before the child gets a chance to set it. It is the later that we see above, the parent running before the child, thus the wrong pgid.
To avoid these issues, when setting the process group of a child,
you should call setpgid()=/=setpgrp() in both the parent and the
child before anything depends on those values. In this way, you can
disambiguate the runtime process, it will not matter which runs
first, the parent or the child, the result is always the same, the
child is placed in the appropriate process group. Below is an
example of that and the output.
/*setpgid.c*/
int main(int argc, char * argv[]){
pid_t cpid, pid, pgid, cpgid; //process id's and process groups
cpid = fork();
if( cpid == 0 ){
/* CHILD */
//set process group to itself
setpgrp(); //<---------------------------!
//print the pid, and pgid of child from child
pid = getpid();
pgid = getpgrp();
printf("Child: pid:%d pgid:*%d*\n", pid, pgid);
}else if( cpid > 0 ){
/* PARRENT */
//set the proccess group of child
setpgid(cpid, cpid); //<------------------!
//print the pid, and pgid of parent
pid = getpid();
pgid = getpgrp();
printf("Parent: pid:%d pgid: %d \n", pid, pgid);
//print the pid, and pgid of child from parent
cpgid = getpgid(cpid);
printf("Parent: Child's pid:%d pgid:*%d*\n", cpid, cpgid);
}else{
/*ERROR*/
perror("fork");
_exit(1);
}
return 0;
}
#> ./setpgid Parent: pid:20335 pgid: 20335 Parent: Child's pid:20336 pgid:*20336* Child: pid:20336 pgid:*20336*
8 Process Groups and Terminal Signaling
Where process groups fit into the ecosystem of process settings is
within the terminal settings. Let's return the terminal control
function, tcsetpgrp(). Before, we discussed this function as
setting the foreground processes, but just from its name
tcsetpgrp(), it actually sets the foreground process group.
8.1 Foreground Process Group
This distinction is important because of terminal signaling. We know
now that when we execute a pipeline, the shell will fork all the
process in the job and place them in the same process group. We also
know that when we use special control keys, like Ctrl-c or
Ctrl-z that the terminal will deliver special signals to the
foreground job, such as indicating to terminate or stop. For
example, this sequence of shell interaction makes sense:
#> sleep 10 | sleep 20 | sleep 30 | sleep 50 & [1] 24253 #> ps PID TTY TIME CMD 4038 pts/3 00:00:00 bash 24250 pts/3 00:00:00 sleep 24251 pts/3 00:00:00 sleep 24252 pts/3 00:00:00 sleep 24253 pts/3 00:00:00 sleep 24254 pts/3 00:00:00 ps #> fg sleep 10 | sleep 20 | sleep 30 | sleep 50 ^C #> ps PID TTY TIME CMD 4038 pts/3 00:00:00 bash 24255 pts/3 00:00:00 ps
We started the sleep commands in the background, we see that there
are 4 instances of sleep running, and we can move them from the
background to the foreground, were they are signaled with Ctrl-c to
terminate via the terminal. All good, right? There is something
missing: Given that there are multiple processes running in the
foreground, how does the terminal know which of those to signal to
stop or terminate signal? How does it differentiate which processes
are in the foreground?
The answer is, the terminal does not identify foreground process individually. Instead, it identifies a foreground process group. All processes associated with the foreground job are in the foreground process group, and instead of signalling processes individually both shell and the terminal think of execution in terms of process groups.
8.2 Orphaned Stopped Process Groups
Process group interaction has other side effects when you consider
programs that fork children. For example, consider the program
(orphan) below which simply forks a child, and then both child a
parent loop forever:
/*orphan.c*/
int main(int argc, char * argv[]){
pid_t cpid;
cpid = fork();
if( cpid == 0 ){
/* CHILD */
//child loops forever!
while(1);
}else if( cpid > 0 ){
/* PARRENT */
//Parrent loops forever
while(1);
}else{
/*ERROR*/
perror("fork");
_exit(1);
}
return 0;
}
If we were to run this program, we can see that, yes, indeed, it
forks and now we have two versions of orphan running in the same
process group.
#> ./orphan & [1] 24468 #> ps -o pid,pgid,ppid,comm PID PGID PPID COMMAND 4038 4038 4037 bash 24468 24468 4038 orphan 24469 24468 24468 orphan 24470 24470 4038 ps
Moving the orphan program to the foreground, it can then be
terminated by the terminal using Ctrl-c.
#> fg ./orphan ^C #> ps -o pid,pgid,ppid,comm PID PGID PPID COMMAND 4038 4038 4037 bash 24471 24471 4038 ps
The resulting termination is for both parent and child, which is as expected since they are both in the foreground process group. While we might expect an orphan to be created, this does not occur. However, let's consider the same program, but this time, the child is placed in a different process group as the parent:
/*orphan_group.c*/
int main(int argc, char * argv[]){
pid_t cpid;
cpid = fork();
if( cpid == 0 ){
/* CHILD */
//set process group to itself
setpgrp();
//child loops forever!
while(1);
}else if( cpid > 0 ){
/* PARRENT */
//set the proccess group of child
setpgid(cpid, cpid);
//Parrent loops forever
while(1);
}else{
/*ERROR*/
perror("fork");
_exit(1);
}
return 0;
}
Let's do the same experiment as before:
#> ./orphan_group & [1] 24487 #> ps -o pid,pgid,ppid,comm PID PGID PPID COMMAND 4038 4038 4037 bash 24487 24487 4038 orphan_group 24488 24488 24487 orphan_group 24489 24489 4038 ps #> fg ./orphan_group ^C #> ps -o pid,pgid,ppid,comm PID PGID PPID COMMAND 4038 4038 4037 bash 24488 24488 1 orphan_group 24490 24490 4038 ps
This time, yes, we see that we have created an orphan process. This
is clear from the PPID field which indicates that the parent of
the orphan_group program is init, which inherits all orphaned
processes. This happens because the terminal signal Ctrl-c is
delivered to the foreground process group only, but the child is
not in that group. The child is in its own process group and never
recieves the signal, and, thus, never terminates. It just continues
on its merry way never realizing that it just lost its parent. In
this examples lies the danger of using process groups; it's very
easy to create a bunch of orphans that will just cary on if not
killed. To rid yourself of them, you must explictely kill them with
a call like killall
#> killall orphan_group #> ps -o pid,pgid,ppid,comm PID PGID PPID COMMAND 4038 4038 4037 bash 24494 24494 4038 ps
And good riddance …
9 Resource Duplication Across Forks
Recall, from our discussion of fork() and process duplication, the
entire process is duplicated, not just the code, but also all the
state of the process. This includes the entire state of memory, such
as the values of variables. For example, consider the program below
that will fork 5 children tracked with a variable i, which is
printed from the child, then manipulated in the child, and printed
again in the parent.
/*shared_variable.c*/
int main(int argc, char * argv[]){
int status;
pid_t cpid, pid;
int i=0;
while(1){ //loop and fork children
cpid = fork();
if( cpid == 0 ){
/* CHILD */
pid = getpid();
printf("Child: %d: i:%d\n", pid, i);
//set i in child to something differnt
i *= 3;
printf("Child: %d: i:%d\n", pid, i);
_exit(0); //NO FORK BOMB!!!
}else if ( cpid > 0){
/* PARENT */
//wait for child
wait(&status);
//print i after waiting
printf("Parent: i:%d\n", i);
i++;
if (i > 5){
break; //break loop after 5 iterations
}
}else{
/* ERROR */
perror("fork");
return 1;
}
//pretty print
printf("--------------------\n");
}
return 0;
}
And we can see the output of this program
>./shared_variables Child: 3833: i:0 Child: 3833: i:0 Parent: i:0 -------------------- Child: 3834: i:1 Child: 3834: i:3 Parent: i:1 -------------------- Child: 3835: i:2 Child: 3835: i:6 Parent: i:2 -------------------- Child: 3836: i:3 Child: 3836: i:9 Parent: i:3 -------------------- Child: 3837: i:4 Child: 3837: i:12 Parent: i:4 -------------------- Child: 3838: i:5 Child: 3838: i:15 Parent: i:5
Looking through the output, we can see each of the 5 children
identified by their process id, and we can track the state of the
variable i. It is initialized in the parent prior to the fork, and
that value is duplicated to the child, as indicated by the first
child print. The child then multiplies i by 3, and prints the
value again, which is indicated by the second child
print. Meanwhile, the parent is waiting for the child to terminate
with a call to wait(), and then prints its own view of the
variable i, which is unchanged.
The program demonstrates how duplication occurs across a fork. The current state of the parent is duplicated to the child, but additional edits by the child are on its own version of the memory not the parents, which also has its own version of the memory.
9.1 File Descriptor's across Forks
All values duplicate in a process are duplicated across a fork, which brings up some interesting situations, like what happens when the process has open file descriptors. For example:
int fd = open( .... );
cpid = fork();
if( cpid == 0){
/*CHILD*/
//reading from same file as parent?
read(fd, ....)
}else if (cpid > 0){
/*PARENT*/
//reading from same file as child?
read(fd, ....)
}
First, consider that the reference to an open file, a file
descriptor, is just an integer number (fd above) that is used by
the operating system to look up the open file in the file
descriptor table. The entry in the table contains a number of
information, including what point in the file is currently being
referenced. For example, if you read 10 bytes from a file
descriptor, and then some point in later in the program read 10
bytes again, you do not reread the same 10 bytes, instead you read
the next 10 bytes. This is accomplished via the data stored in the
file descriptor table which tracks the current place in the file.
Returning to the example above, the value of fd should be
duplicated from parent to child. The question is, how does this
affect the data stored in the file descriptor table. Technically,
the value of fd, e.g., a number like 3, is the same for parent and
child, and should then reference the same entry in the file
descriptor table, and it does. Interestingly, it not only references
the same entry in the table, but that there is nothing wrong with
two differences processes reading from the same file, which will
stay in sync.
You can see this in the program below where a parent and child process alternate between reading 1 byte at a time from a file.
/*shared_file.c*/
int main(int argc, char * argv[]){
int fd, status;
pid_t cpid;
char c;
if ( argc < 2){
fprintf(stderr, "ERROR: Require path\n");
return 1;
}
//shared between all children and parent
if( (fd = open(argv[1], O_RDONLY)) < 0){
perror("open");
return 1;
}
while (1){
cpid = fork();
if( cpid == 0 ){
/* CHILD */
//try and read 1 byte from file
if( read(fd, &c, 1) > 0){
printf("c: %c\n", c); // print the char
_exit(0); //exit with status 0 on sucess read
}else{
//no more to read
_exit(1); //exit with status 1 on failed read
}
}else if ( cpid > 0){
/* PARENT */
//wait for child to read first
wait(&status);
//if exit status 1, break the loop, no more to read
if( WEXITSTATUS(status) ){
break;
}
//now parent reads a byte
if( read(fd, &c, 1) > 0){
printf("p: %c\n", c); // print the char
}
}else{
/* ERROR */
perror("fork");
return 1;
}
}
//done reading the file
close(fd);
return 0;
}
Prior to entering the loop, a file is open, and after each fork, the file descriptor is duplicated to the child, which tries to read a byte and print it, returning either success or failure if there is no more bytes to read. Meanwhile, the parent is waiting for the child terminate, checks the status, and if there is more of the file to read, the parent then reads and prints a byte. The result is that the program alternates between reading 1 byte at a time from a file between parent and a sequence of children. Here's the output of running the program, "c:" is a print from a child and "p:" is a print from the parent.
#> cat helloworld.txt Hello World! #> ./shared_files helloworld.txt c: H p: e c: l p: l c: o p: c: W p: o c: r p: l c: d p: ! c:
10 Inter-Process Communication and Pipes
Where duplication of file descriptors becomes interesting is when you consider the possibility for inter-process communication. So far, we've seen very limited inter-process communication through the setting of exit status or termination conditions; a parent can check the status of a terminating child and perform some action based on that. But, how can a child communicate to a parent? Or, how can we communicate more than just a short number?
We know that process can communicate a large amount of information over a text stream with a pipe on the command line, and, moreover, this is vital part of the Unix design philosophy. What we are going to look at now is how we can create pipes to perform inter process communicating, leveraging the duplication of file descriptors across forks.
10.1 Hello pipe()
The pipe() system call is used to create a set of connected file
descriptors, one for reading and one for writing. Whatever data is
written to the write end of the pipe can be read from the read end
of the pipe. Here's the generally setup:
int pfd[2]; //pfd[0] reading end of pipe
//pfd[1] writing end of pipe
//open the pipe
if( pipe(pfd) < 0){
perror("pipe");
return 1;
}
Now pfd and array of two integers for file descriptors is set
such that pfd[0] is the reading end (like 0 for stdin) and
pfd[1] is the writing end (like 1 for stdout). We can now use the
two file descriptors to transfer data. For example, here is the
hello-world program for pipes:
int main(int argc, char * argv[]){
//print hello world through a pipe!
char hello[] = "Hello World!\n";
char c;
int pfd[2]; //pfd[0] reading end of pipe
//pfd[1] writing end of pipe
//open the pipe
if( pipe(pfd) < 0){
perror("pipe");
return 1;
}
//write hello world to pipe
write(pfd[1], hello, strlen(hello));
//close write end of pipe
close(pfd[1]);
//read hello world from pipe, write to stdout
while( read(pfd[0], &c, 1)){
write(1, &c, 1);
}
//close the read end of the pipe
close(pfd[0]);
return 0;
}
The program writes "Hello World!\n" to the write end of the pipe, and then reads it back from read end of the pipe, writing the result to stdout.
10.2 Pipes Bursting! and Blocking!
There are a number of very reasonable questions you should be asking at this point:
- Where does the data go that's written to the pipe? It must be stored somewhere because we read it back later.
- How much data can we write to the pipe before we have to read it? Computers are finite machines, at some point, the pipe must burst!
To answer the first question, where does the data go, we can refer back to our discussions of I/O buffering. We know that the O.S. and the C standard library provides some amount of buffering on reads and writes. From the perspective of the program, it sees a pipe file descriptor like any other file descriptor, but instead of being hooked into a file in the file system, it actually points to a buffer, a storage space, in the kernel. Reading and writing from the pipe is just a matter of adding data to the buffer and remove data from the buffer.
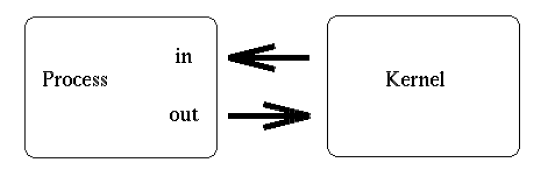
Figure 7: In and Out of a pipe communicate through the kernel (source tldp.org)
To answer the second question, how much data, we can write a program and find out. Below, here is a program that opens a pipe, and writes 'A' to the pipe in an loop, which will break when the write fails. It also maintains a count of how many times 'A' was written.
/*pipe_block.c*/
int main(int argc, char * argv[]){
char c = 'A';
int i;
int pfd[2]; //pfd[0] reading end of pipe
//pdf[1] writing end of pipe
//open the pipe
if( pipe(pfd) < 0){
perror("pipe");
return 1;
}
//write A's to pipe until it's full
i = 0;
while( write(pfd[1], &c, 1) > 0){
printf("%d\n",i);
i++;
}
perror("write");
//close write end of pipe
close(pfd[1]);
//read from pipe?!?
while( read(pfd[0], &c, 1)){
write(1, &c, 1);
}
close(pfd[0]);
return 0;
}
Before we give the output, let's consider some possibilities. Two come to mind.
- First, we'll write as many 'A's as possible counting and printing
all along, and then the
write()will fail, -1 is returned. The result is the count and that many A's. Essentially, once the pipe is full, a write fails. - Another possibilities is that once the pipe is full, and you try and do that last write, it doesn't fail, it just makes the program wait until the pipe is no longer full, that is, another program has read from it. Essentially, once the pipe is full, the write blocks.
Two possibilities, what happens? We don't need to squint, we can run the program, and here's the output.
#>./pipe_block 1 2 (...) 65534 65535 ^C
It's number 2: when the pipe is full, the write will block. We can
see this because the program printed all the numbers and the it
reached a max, hung, and was terminated with Ctrl-c. The number
65535 is also meaningful, it is 216 -1, which is as good a choice
for the pipe size.
However, it could have been number 1, a failed write. The Operating
System allows you to change the way read/write call function
depending on the file descriptor. The way to do this is using the
fcntl() or file descriptor control. This system call allows you
to set a number of options (or flags) about the interaction with a
file descriptor. One such flag is an option to set the file
descriptor to be non-blocking:
//set pipe to not block
fcntl(pfd[1], F_SETFL, O_NONBLOCK);
You can read more about other flags in the man pages man 2 fcntl,
but the above call just sets the write end of the pipe to be
non-blocking. If we rerun the program with that setting:
#>./pipe_nonblock 1 2 (...) 65534 65535 write: Resource temporarily unavailable AAAAAAAAAAAAAAAAAAAAAAA (...)
The write() will fail with a resource unavailable error, the pipe
is full, and then the rest of the program can proceed, printing an
absurd number of 'A's.
10.3 Inter Process Pipes
We now have a pretty good understanding of a pipe, so let's see how to use them to do inter-process communication. Like before, we are going to leverage the fact that after a fork, the process is fully duplicated, which would include the pipe. With the pipe file descriptors in the parent and child, it becomes fairly intuitive to read and write data between them. Here's a really simple program that will send data from the parent to the child across a pipe, and then the child will write what it read to stdout.
/*pipe_hello_to_child.c*/
int main(int argc, char * argv[]){
//print hello world through a pipe! To child!
char hello[] = "Hello World!\n";
char c;
int pfd[2]; //pfd[0] reading end of pipe
//pfd[1] writing end of pipe
pid_t cpid;
int status;
//open a pipe, pfd[0] for reading, pfd[1] for writing
if ( pipe(pfd) < 0){
perror("pipe");
return 1;
}
cpid = fork();
if( cpid == 0 ){
/* CHILD */
//close the writing end in child
close(pfd[1]);
//try and read 1 byte from pipe, write byte stdout
while( read(pfd[0], &c, 1) > 0){
write(1, &c,1);
}
//close pipe
close(pfd[0]);
_exit(0);
}else if ( cpid > 0){
/* PARENT */
//close reading end in parent
close(pfd[0]);
//write hello world to pipe
write(pfd[1], hello, strlen(hello));
//close the pipe
close(pfd[1]);
//wait for child
wait(&status);
}else{
/* ERROR */
perror("fork");
return 1;
}
return 0;
}
The program is just like the hello_pipe program, but this time,
the parent writes "Hello World\n" to the pipe, but it's the child
that reads it out and writes it to standard output. While this is a
silly example, it is easy to start to see how pipe's can be sued to
communicate across process.
11 Duplicating File Descriptor and Pipelines
The other place we've seen pipes is in the context of bash command lines.
cat sample_db.csv | cut -d "," -f 5 | sort | uniq | wc -l
As we know, he pipe symbol says, connect the standard output of one
program with the standard input of another. From the context of the
pipe() system call, we can begin to imagine how that might be
done, but there's a piece missing. With the pipe() system call, we
get the input and output file descriptors which are used for inter
process communication, but for the commands above, they read and
write from stdout and stdin directly. How do we make them use the
pipe instead? This is accomplished by file descriptor duplication, a
process that overwrites a file descriptor with another, and this can
be done with the standard file descriptors.
11.1 Duplicating a File Descriptor
The system call to duplicate file descriptors is dup(), but we
will use the slightly easier to manage dup2() version of the
system call. Here is the prototype for dup2():
int dup2(int filedes, int filedes2);
It will duplicate the file descriptor fildes onto the file
descriptor filedes2; essentially, if you were to read and write
from fildes2 now, it would be the same as reading and writing
from filedes. The two file descriptors do not have the same
value, one might be 4 and other 7, but their entries in the file
descriptor table has been duplicated.
To see this in action, let's look at a hello world program of file duplication:
/*hello_dup.c*/
int main(int argc, char * argv[]){
//print hello world to a file with dup
int fd;
//check args
if ( argc < 2){
fprintf(stderr, "ERROR: Require destination path\n");
return 1;
}
//open destination file
if( (fd = open(argv[1], O_WRONLY | O_TRUNC | O_CREAT , 0644)) < 0){
perror("open");
return 1;
}
//close standard out
close(1);
//duplicate fd to stdout
dup2(fd, 1);
//print to stdout, which is now duplicated to fd
printf("Hello World!\n");
return 0;
}
In this program, we open a new file at the file descriptor fd and
we wish to make that file descriptor the same as standard out. The
first step is to close standard out, and the duplicate the new fd
to standard out. Now, whenever we print to standard out it will
actually print to the file descriptor. Which is exactly what
happens when we run the program:
#> ./hello_dup hello #> cat hello Hello World!
You might notice, that this is the same as standard output
redirection in the shell using the > symbol, and, in fact, this
is how the shell implements that redirection.
11.2 Setting up a pipeline
Finally, we have all the information we need to set up a basic pipeline between two process that uses the stdin/stdout mechanisms. The procedure is straightforward, we need a pipe and the read and write ends are duplicated to standard output and input of the processes that are communicating.
Let's consider doing this for the simple program which will set up
a pipeline like so: parent | child. Here is such a program:
/*pipe_dup.c*/
int main(int argc, char * argv[]){
int status;
int pfd[2];
pid_t cpid;
char c;
//open a pipe, pfd[0] for reading, pfd[1] for writing
if ( pipe(pfd) < 0){
perror("pipe");
return 1;
}
//Setup a pipe between child 1 and child 2, like:
// parent | child
cpid = fork();
if( cpid == 0 ){
/* CHILD 1*/
//close stdin
close(0);
//duplicate reading end to stdin
dup2(pfd[0], 0);
//close the writing end
close(pfd[1]);
//try and read 1 byte from stding and write stdout
while( read(0, &c, 1) > 0){ //stdin now pipe!
write(1, &c,1); //this is still stdout
}
exit(0);
} else if ( cpid > 0){
/* PARENT */
//close stdout
close(1);
//duplicate writing end to stdout
dup2(pfd[1], 1);
//close reading end
close(pfd[0]);
//read and read 1 byte from stdin, write byte to pipe
while( read(0,&c,1) > 0){
write(1, &c, 1);
}
//close the pipe and stdout
close(pfd[1]);
close(1);
//wait for child
wait(&status);
}else{
/* ERROR */
perror("fork");
return 1;
}
return 0;
}
First, a pipe is created before the fork. In the parent, standard out and the read end of the pipe are closed, and then the write end of the pipe is duplicated onto standard out. Whenever the parent writes to standard out, it is actually writing to the pipe. In the child, it similarly closes the write end of the pipe and standard in, and then duplicates the read end of the pipe to standard input. Now, whenver the child reads from standard input it is actually reading from the pipe, which the parent will write to.
It's a pipeline! Not a very useful pipeline. The parent reads its
data from standard input, sends it to the child through the pipe,
which writes the data to standard output. It's a glorified cat
program that requires two process, but a pipeline none the less. We
can see that it is doing that by running it in the command line:
#> ./pipe_dup hello hello ^Z [1]+ Stopped ./pipe_dup #> ps -o pid,pgid,comm PID PGID COMM 418 418 bash 4772 4772 emacs 5188 5188 ./pipe_dup 5189 5188 ./pipe_dup
The "hello" typed into the terminal was read by the parent, piped to the child, and then printed back to the terminal. If we stop the program and run ps, we can see that there are two processes running. It works! Now, the next step is implementing more complicated pipelines, which is a task for another lesson.