Unit 1: The Unix System
Table of Contents
1 UNIX and You
1.1 The 1000 Foot View of the UNIX system

Why UNIX?
- UNIX is an important OS in the history of computing
- Two major OS variants, UNIX-based and Windows-based
- Used in a lot of back-end systems and personal computing
- UNIX derivatives are open source, and well known to the community and developed in the open where we can study and understand them.
- The skills you learn on UNIX will easily translate to other OS platforms because all UNIX-based systems share standard characteristics.
1.2 Unix History
Unix has a rich history dating back to the development of Multics and then Unic system. First developed at AT&T Bell labs in the early 70's. These early forms have dispersed and integrated into computing, include the Ubuntu, Debian Linux Variants variants we use here and the MacOS, BSD variants. Unix is even run on the mobile platforms, both iOS and Android are based on Unix system architecture.
1.3 The UNIX Components
The UNIX-Computer ecosystem can be divided into three main parts:
- User Space: Defines the applications, libraries, and standard utilities that are user accessible. When we write a program, it is from this perspective that we operate, without concern for the underlying components. For example, writing a "Hello World" program on any computer is the same from the user-perspective, but might be different when it comes to actually executing the program and writing "Hello World" to the terminal.
- Kernel Space: This refers to the operations of OS that manage the interface between user actions and the hardware. It is the central part of the OS, and its primary job is to pair user applications with the underlying hardware and allow multiple programs to share singular hardware components. For example, how does a user input event, such as typing 'a' on the keyboard, get translated into 'a' appearing on the screen? Or, how does two programs both read from disc at the same time or run on the CPU at the same time?
- Hardware: The underlying physical components of the computer. These include Input/Output devices, like keyboards and monitors, the CPU which does calculations, the memory components, and the network interface.
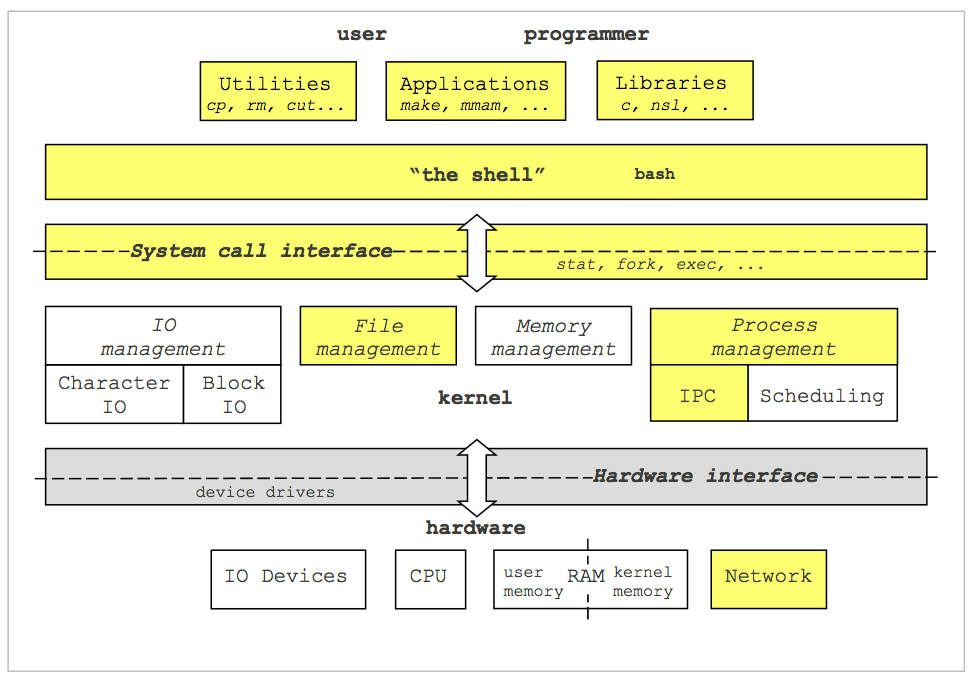
The OS'es primary task is to manage services as an interface between the user and the hardware. Examples include:
- File System: managing files on the user
- Device I/O: managing input from devices
- Processes: Starting, running, and stopping programs, and allowing multiple programs to run at once, i.e., program multiprogramming.
- Memory Management: Allocating runtime memory for process and separating memory between process and between user-space and the kernel-space
From a user of the OS, you will see these interactions from two perspectives:
- Shell: You will use the shell to interact with the OS
- System Call API: You will program in C to interact with the OS
The big part of this interaction comes from the System Call API, which you will use C. Why C?
- C is a low level language
- The OS is written in C
- Understanding the OS and C together is a natural process and will make you a better programmer
2 UNIX Design Philosophy
The UNIX Design Philosophy is best exemplified through a quote by Doug McIlroy, a key contributor to early UNIX systems:
This is the UNIX philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
All the UNIX command line tools we've looked at so far meet this philosophy, and the tools we will program in the class will as well.
2.1 Write programs that do one thing and do it well
If we look at the command line tools for processing files, we see
that there is a separate tool for each task. For example, we do not
have a tool called headortail that can take either the first or
last lines of a file. We have separate tools for each of the
tasks.
While this might seem like extra work, it actually enables the user to be more precise about what he/she is doing, as well as be more expressive. It also improves the readability and comprehension of commands; the user doesn't have to read lots of command line arguments to figure out what's going on.
2.2 Write programs that work well together
The command line tools we look at also inter-operate really well because they
complement each other. For example, you can use cut to get a field from
structure data, then you can use grep to isolate some set of those fields,
and finally you can use wc to count how many fields remain.
2.3 Write programs to handle text streams
Finally, the ability to handle text streams is the basis of the pipeline that enables small and simple UNIX commands to be "glued" together to form more complex and interesting UNIX operations.
This philosophy leads to the development of well formed UNIX command line tools that have the three properties:
- They can take input from the terminal, through a pipe or redirection, or by reading an input file provided as an argument
- They write all non-error output back to the terminal such that it can be read as input by another command via a pipe or can be redirected to a file.
- They do not write error information to standard output in a way that does not interfere with a pipeline.
This process of taking input from the terminal and writing output to the terminal is the notion of handling text streams through the pipeline. In this lecture, we will look at this process in more detail.
3 Standard Input, Standard Output, and Standard Error
Every UNIX program is provided with three standard file streams or standard file descriptors to read and write input from.
- Standard Input (
stdinfile stream, file descriptor 0): The primary input stream for reading information printed to the terminal - Standard Output (
stdoutfile stream, file descriptor 1): The primary output stream for printing information and program output to the terminal - Standard Error (
stderrfile stream, file descriptor 2): The primary error stream for printing information to the terminal that resulted from an error in processing or should not be considered part of the program output.
3.1 Pipelines
Pipelines are sequence of processes, executed in parallel, where the standard output of one program to the standard input of another program, via a pipe, provides dependencies (e.g., one program waiting on the output of another before proceedings) such that programs complete in series. This fits into the UNIX design philosophy well by allowing smaller programs to work well together, connecting computation via a text stream.
We denote the piping between programs in a pipeline using the the | (pipe
symbol). Consider this simple C++ program that reads a string from a user and
prints it in reverse:
#include <iostream>
using namespace std;
int main(){
string s;
cin >> s; //read from stdin
for(int i=s.size()-1;i>=0;i--)
cout << s[i]; //write to stdout
cout << endl;
}
We can run this program directly on the command line like so:
$ ./reverse Hello olleH
But that requires us the user to type, but what if we could use
another program to produce the output. There is a built in command
called echo that will do just that:
$ echo "Hello" Hello $ echo "Hello" | ./reverse olleH
This time, we have piped the output of the echo command to the
input of the reverse command, producing the same output as
before.
Now, what if we wanted to reverse our reversed output? We could also pipe that output again to the next program.
$ echo "Hello" | ./reverse | ./reverse Hello
This is the power of a pipeline, and if you imagined, there is nothing stopping us from doing more complicated stuff.
3.2 Sample Commands Using stdin and stdout
As an example of using pipes to control standard input and output,
lets look at the head and tail command, each either prints the
first lines or last lines of a file, respectively.
For example, the file file1 in this example has 1000 lines, each
labeled. We could just print the first 10 lines like so:
$ head file1 file1 line 1 file1 line 2 file1 line 3 file1 line 4 file1 line 5 file1 line 6 file1 line 7 file1 line 8 file1 line 9 file1 line 10
A similar command for tail prints the last 10 lines
$ tail file1 file1 line 991 file1 line 992 file1 line 993 file1 line 994 file1 line 995 file1 line 996 file1 line 997 file1 line 998 file1 line 999 file1 line 1000
We could connect these two commands together to print any consecutive lines of a file. For example, suppose we want to print lines 800-810:
$ head -810 file1 | tail file1 line 801 file1 line 802 file1 line 803 file1 line 804 file1 line 805 file1 line 806 file1 line 807 file1 line 808 file1 line 809 file1 line 810
The -810 flag to head, says to print the first 810, then tail
reads from stdin and prints the last 10 of those lines, giving us
the lines between 800 and 810.
The cat command, which you should be familiar with already, prints
each of the files specified as its arguments to the terminal. For
example, consider the following two files:
$ cat BeatArmy.txt Beat Army $ cat GoNavy.txt Go Navy $ cat GoNavy.txt BeatArmy.txt Go Navy Beat Army
cat will also read from the stdin using a pipe with no arguments,
but we can also use - by itself to say when in the sequence of
files to read from stdin. For example.
$ cat GoNavy.txt | cat BeatArmy.txt - BeatArmy.txt Beat Army Go Navy Beat Army
So we can now hook up our previous command to surround the 800-810 file with "Go Navy" and "Beat Army"
$ head -810 file1 | tail | cat GoNavy.txt - BeatArmy.txt Go Navy file1 line 801 file1 line 802 file1 line 803 file1 line 804 file1 line 805 file1 line 806 file1 line 807 file1 line 808 file1 line 809 file1 line 810 Beat Army
3.3 Pipes and stderr
One challenge with a pipeline is that all the output of a program gets redirected to the input of the next program. What if there was a problem or error to report?
Given the description of the standard file descriptors, we can better understand a pipelines with respect to the standard file descriptors.
Head writes to stdout--. .---the stdout of head is the stdin of cat
| |
v v
head -3 BAD_FILENAME | cat GoNavy.txt - BeatArmy.txt
\_/
|
A pipe just connects the stdout of
one command to the stdin of another
The pipe (|) is a semantic construct for the shell to connect the
standard output of one program to the standard input of another
program, thus piping the output to input.
The fact that input is connected to output in a pipeline actually
necessitates stderr because if an error was to occur along the
pipeline, you would not want that error to propagate as input to the
next program in the pipeline especially when the pipeline can
proceed despite the error. There needs to be a mechanism to report
the error to the terminal outside the pipeline, and that mechanism
is standard error.
As an example, consider the the case where head is provided a bad
file name.
#> head -3 BAD_FILENAME| cat BeatArmy.txt - GoNavy.txt head: BAD_FILENAME: No such file or directory <--- Written to stderr not piped to cat Go Navy! Beat Army!
Here, head has an error BAD_FILENAME doesn't exist, so head
prints an error message to stderr and does not write anything to
stdout, and thus, cat only prints the contents of the two files
to stdout. If there was no stderr, then head could only report
the error to stdout and thus it would interfere with the pipeline;
head: BAD_FILENAME: No such file or directory
is not part of the first 3 lines of any file.
3.4 Redirecting stdin, stdout, and stderr
In addition to piping the standard file streams, you can also
redirect them to a file on the filesystem. The redirect symbols
is > and <. Consider a dummy command below:
cmd < input_file > output_file 2> error_file
This would mean that cmd (a fill in for a well formed UNIX
command) will read input from the file input_file, all output
that would normally go to stdout is now written to output_file,
and any error messages will be written to error_file. Note that 2
and the > together (2>) indicates to redirect file descriptor
2, which maps to stderr (see above).
You can also use redirects interspersed in a pipeline like below.
cmd < input_file | cmd 2> error_file | cmd > output_file
However, you cannot mix two redirects for the same standard stream, like so:
cat input_file > output_file | head
This command will result in nothing being printed to the screen
via head and all redirected to output_file. This is because the > and
< redirects always take precedence over a pipe, and the last >
or < in a sequence takes the most precedence. For example:
cat input_file > out1 > out2 | head
will write the contents of the input file to the out2 file and
not to out1.
Output redirects will create the file if it doesn't already exist or will
truncate the file if it does exists. By truncate, we mean that the
redirection will erase an existing file and create a new one. There are
situations where, instead, you want to append to the end of the file, such
as accumulating log files. You can do such output redirects with >>
symbols, double greater-then signs. For example,
cat input_file > out cat input_file >> out
will produce two copies of the input file concatenated together in
the output file, out.
4 Reading and Writing to /dev/null and other /dev's
There are times when you are building UNIX commands that you want to redirect your output or error information to nowhere … you just want it to disappear. This is a common enough need that UNIX has built in files that you can redirect to and from.
Perhaps the best known is /dev/null. Note that this file exists in
the /dev path which means it is not actually a file, but rather a
device or service provided by the UNIX Operating System. The
null device's sole task in life is to turn things into null or
zero them out. For example, consider the following pipeline with
the BAD_FILENAME from before.
#> head -3 BAD_FILENAME 2> /dev/null | cat BeatArmy.txt - GoNavy.txt Go Navy! Beat Army!
Now, we are redirecting the error from head to /dev/null, and thus it goes
nowhere and is lost. If you try and read from /dev/null, you get nothing,
since the null device makes things disappear. The below command is similar
to using touch to create a new, empty file since head reads nothing and then
writes nothing to file, creating an empty file.
head /dev/null > file.
You may think that this is a completely useless tool, but there are
plenty of times where you need something to disappear – such as
input or output or your ic221 homework – that is when you need
/dev/null.
4.1 Other useful redirect dev's
UNIX also provides a number of device files for getting information:
/dev/zero: Provide zero bytes. If you read from/dev/zeroyou only get zero. For example the following writes 20 zero bytes to a file:
head -c 20 /dev/zero > zero-20-byte-file.dat
/dev/urandom: Provides random bytes. If you read from/dev/urandomyou get a random byte. For example the following writes a random 20 bytes to a file:
head -c 20 /dev/urandom > random-20-byte-file.dat
4.2 (Extra) A note on the /dev directory and the OS
The files you find in /dev are not really files, but actually
devices provided by the Operating System. A device generally
connects to some input or output component of the OS. The three
devices above (null, zero, and urandom) are special functions
of the OS to provide the user with a null device (null), a
consistent zero base (zero) , and a source of random entropy
(urandom).
If we take a closer look at the /dev directory you see that there
is actually quite a lot going on here.
alarm hidraw0 network_throughput ram9 tty13 tty35 tty57 ttyS2 vboxusb/ ashmem hidraw1 null random tty14 tty36 tty58 ttyS20 vcs autofs hpet oldmem rfkill tty15 tty37 tty59 ttyS21 vcs1 binder input/ parport0 rtc@ tty16 tty38 tty6 ttyS22 vcs2 block/ kmsg port rtc0 tty17 tty39 tty60 ttyS23 vcs3 bsg/ kvm ppp sda tty18 tty4 tty61 ttyS24 vcs4 btrfs-control lirc0 psaux sda1 tty19 tty40 tty62 ttyS25 vcs5 bus/ log= ptmx sda2 tty2 tty41 tty63 ttyS26 vcs6 cdrom@ loop0 pts/ sg0 tty20 tty42 tty7 ttyS27 vcsa cdrw@ loop1 ram0 sg1 tty21 tty43 tty8 ttyS28 vcsa1 char/ loop2 ram1 shm@ tty22 tty44 tty9 ttyS29 vcsa2 console loop3 ram10 snapshot tty23 tty45 ttyprintk ttyS3 vcsa3 core@ loop4 ram11 snd/ tty24 tty46 ttyS0 ttyS30 vcsa4 cpu/ loop5 ram12 sr0 tty25 tty47 ttyS1 ttyS31 vcsa5 cpu_dma_latency loop6 ram13 stderr@ tty26 tty48 ttyS10 ttyS4 vcsa6 disk/ loop7 ram14 stdin@ tty27 tty49 ttyS11 ttyS5 vga_arbiter dri/ loop-control ram15 stdout@ tty28 tty5 ttyS12 ttyS6 vhost-net dvd@ lp0 ram2 tpm0 tty29 tty50 ttyS13 ttyS7 watchdog dvdrw@ mapper/ ram3 tty tty3 tty51 ttyS14 ttyS8 watchdog0 ecryptfs mcelog ram4 tty0 tty30 tty52 ttyS15 ttyS9 zero fb0 mei ram5 tty1 tty31 tty53 ttyS16 uinput fd@ mem ram6 tty10 tty32 tty54 ttyS17 urandom full net/ ram7 tty11 tty33 tty55 ttyS18 vboxdrv fuse network_latency ram8 tty12 tty34 tty56 ttyS19 vboxnetctl
You will learn more about /dev's in your OS class, but for now you
should know that this is a way to connect the user-space with the
kernel-space through the file system. It is incredibly powerful and
useful, beyond just sending stuff to /dev/null.
Each of the files is the input to some OS process. For
example, each of the tty information is a terminal that is open on
the computer. The ram refer to what is currently in the computer's
memory. The dvd and cdrom, that is the file that you write and
read to when connecting with the dvd/cd-rom. And the items under
disk, that a way to get to the disk drives.
5 File Permissions and Ownership chmod and chown
Continuing our exploration of the UNIX file system and command line operations, we now turn our attention to the file ownership and permissions. One of the most important services that the OS provides is security oriented, ensuring that the right user access the right file in the right way.
Lets first remind ourselves of the properties of a file that are
returned by running ls -l:
.- Directory?
| .-------Permissions .- Directory Name
| ___|___ .----- Owner |
v/ \ V ,---- Group V
drwxr-x--x 4 aviv scs 4096 Dec 17 15:14 ic221
-rw------- 1 aviv scs 400 Dec 19 2013 .ssh/id_rsa.pub
^ \__________/ ^
File Size -------------' | '- File Name
in bytes |
|
Last Modified --------------'
There are two important parts to this discussion: the owner/group and the permissions. The owner and the permissions are directly related to each other. Often permissions are assigned based on user status to the file, either being the owner or part of a group of users who have certain access to the file.
5.1 File Ownership and Groups
The owner of a file is the user that is directly responsible for the
file and has special status with respect to the file
permission. Users can also be grouped together in group, a
collection of users who posses the same permissions. A file also has
a group designation to specify which permission should apply.
You all are already aware of your username. You use it all the time, and it
should be a part of your command prompt. To have UNIX tell you your username
and connection information on this machine, use the command, who am i:
aviv@unix: ~ $ who am i aviv pts/24 2014-12-29 10:44 (potbelly.academy.usna.edu)
You can use the whoami (no spaces) command to print only your username:
aviv@unix: ~ $ whoami aviv
The first part of the output is the username, for me that is aviv,
for you it will be your username. The rest of the information in
the output refers to the terminal, the time the terminal was
created, and from which host you are connected. We will learn about
terminals later in the semester. (And yes, I name my computers after
pigs.)
You can determine which groups you are in using the groups
command.
aviv@unix: ~ $ groups scs sudo
On this computer, I am in the scs group which is for computer science
faculty members. I am also in the sudo group, which is for users
who have super user access to the machine. Since UNIX is my
personal work computer, I have sudo access.
5.2 The password and group file
Groupings are defined in two places. The first is a file called
/etc/passwd which manages all the users of the system. Here is my
/etc/passwd entry:
aviv@unix: ~ $ grep aviv /etc/passwd
aviv:x:35001:10120:Adam Aviv {}:/home/scs/aviv:/bin/bash
The first two parts of that file describe the userid and
groupid, which are 35001 and 10120, respectively. These numbers
are the actual group and user names, but UNIX nicely converts
these numbers into names for our convenience. The translation
between userid and username is in the password file. The translation
between groupid and group name is in the group file,
/etc/group. Here is the SCS entry in the group file:
aviv@unix: ~ $ grep scs /etc/group scs:*:10120:webadmin,www-data,lucas,slack
There you can see that the users webadmin, www-data, lucas and
slack are also in the SCS group. While my username is not listed
directly, I am still in the scs group as defined by the entry in the
password file.
Take a moment to explore these files and the commands. See what groups you are in.
5.3 File Permissions
We can now turn our attention to the permission string. A permission is simply a sequence of 9 bits broken into 3 octets of 3 bits each. An octet is a base 8 number that goes from 0 to 7, and 3 bits uniquely define an octet since all the numbers between 0 and 7 can be represented in 3 bits.
Within an octet, there are three permission flags, read, write
and execute. These are often referred to by their short hand, r,
w, and x. The setting of a permission to on means that the bit
is 1. Thus for a set of possible permission states, we can uniquely
define it by an octal number
rwx -> 1 1 1 -> 7 r-x -> 1 0 1 -> 5 --x -> 0 0 1 -> 1 rw- -> 1 1 0 -> 6
A full file permission consists of the octet set in order of user, group, and global permission.
,-Directory Bit | | ,--- Global Permission v / \ -rwxr-xr-x \_/\_/ | `--Group Permission | `-- Owner Permission
These define the permission for the user of the file, what users in the same group of the file, and what everyone else can do. For a full permission, we can now define it as 3 octal numbers:
-rwxrwxrwx -> 111 111 111 -> 7 7 7 -rwxrw-rw- -> 111 110 110 -> 7 6 6 -rwxr-xr-x -> 111 101 101 -> 7 5 5
To change a file permission, you use the chmod command and
indicate the new permission through the octal. For example, in
part5 directory, there is an executable file hello_world. Let's
try and execute it. To do so, we insert a ./ in the front to tell
the shell to execute the local file.
> ./hello_world -bash: ./hello_world: Permission denied
The shell returns with a permission denied. That's because the execute bit is not set.
#> ls -l hello_world -rw------- 1 aviv scs 7856 Dec 23 13:51 hello_world
Let's start by making the file just executable by the user, the permission 700. And now we can execute the file:
#> chmod 700 hello_world #> ls -l hello_world -rwx------ 1 aviv scs 7856 Dec 23 13:51 hello_world #> ./hello_world Hello World!
This file can only be executed by the user, not by anyone else because the permissions for the group and the world are still 0. To add group and world permission to execute, we use the permission setting 711:
#> chmod 711 hello_world #> ls -l hello_world -rwx--x--x 1 aviv scs 7856 Dec 23 13:51 hello_world
At times using octets can be cumbersome, for example, when you want to set all the execute or read bits but don't want to calculate the octet. In those cases you can use shorthands.
r,w,xshorthands for permission bit read, write and execute- The
+indicates to add a permission, as in+xor+w - The
-indicates to remove a permission, as in-xor-w u,g,oshorthands for permission bit user, group, and otherashorthand refers to all, applying the permission to user, group, and other
Then we can change the permission
chmod +x file <-- set all the execute bits chmod a+r file <-- set the file world readable chmod -r file <-- unset all the read bits chmod gu+w file <-- set the group and user write bits to true
Depending on the situation, either the octets or the shorthands are preferred.
5.4 Changing File Ownership and Group
The last piece of the puzzle is how do we change the ownership and group of a file. Two commands:
chown user file/directory: change owner of the file/directory to the userchgrp group file.directory: change group of the file to the group
Permission to change the owner of a file is reserved only for the super user for security reasons. However, changing the group of the file is reserved only for the owner.
aviv@unix: demo $ ls -l total 16 -rwxr-x--- 1 aviv scs 9133 Dec 29 10:39 helloworld -rw-r----- 1 aviv scs 99 Dec 29 10:39 helloworld.cpp aviv@unix: demo $ chgrp mids helloworld aviv@unix: demo $ ls -l total 16 -rwxr-x--- 1 aviv mids 9133 Dec 29 10:39 helloworld -rw-r----- 1 aviv scs 99 Dec 29 10:39 helloworld.cpp
Note now the hello world program is in the mids group. I can still execute it because I am the owner:
aviv@unix: demo $ ./helloworld Hello World
However if I were to change the owner, to say, pepin, we get the
following error:
aviv@unix: demo $ chown pepin helloworld chown: changing ownership of ‘helloworld’: Operation not permitted
Consider why this might be. If any user can change the ownership of a file, then they could potentially upgrade or downgrade the permissions of files inadvertently, violating a security requirement. As such, only the super user, or the administrator, can change ownership settings.