Unit 4: I/O System Calls
Table of Contents
1 The Operating System as a Resource
In the past lessons, we've been learning about the C programming language, but now we turn attention back to the operating system and the relationship between the programmer and the operating system.
Recall from earlier lessons that an operating system is a software unit that controls and manages the hardware and system resources of a computer. The operating systems provides two primary features for the programmer:
- Abstraction : The OS provides an abstract execution environment for the programmer to view their program running and using system resources through a unified interface, regardless of the underlying hardware.
- Isolation : The OS ensures that the execution of one program doesn't interfere with the execution of other programs, and that actions of programs can occur concurrently.
To achieve these components, the OS applies a security policy that controls and coordinates access to system resources so that programers do not unintentionally break the abstraction and isolation requirements. The OS'es enforcement of the security policy is implemented through the system call API. Instead of having the programmer directly access resources, an API is used by which the programmer asks the OS to perform protected actions on its behalf. The OS, unlike the programer, is trusted in performing these actions in a way that will not break anything, and the unified framework also simplifies the programmers experience.
The separation between the actions that can be performed by the programmer and those that must be performed by the OS is divided between user-space and kernel-space. Understanding this boundary from a system programming and OS resource perspective is the theme of this lesson.
1.1 OS System Resources
The functions of the OS is to manage system resources. What are system resources? These are the hardware components of the computer that support the execution of a programmer or organization of information. Typically, we describe the set of system resources coordinated by the OS as:
- Device Management : Hardware devices, such as keyboard, monitors, printers, hard drives, etc., are resources managed by the computer. When a programmer wishes to interact with these devices, a unified interface provided by the OS is used.
- Process Management : The invocation and execution of a program, a process, is managed by the OS, including managing its current state, running or stopped, as well as the loading of code.
- Memory Management : The access to physical and virtual memory is controlled by the OS, and a programs memory layout and current allocations is carefully managed.
- File System Management : The OS is also responsible for ensuring that programs can read and write from the filesystem, but also that programs don't corrupt the file sysystem or access files/directory that they do not have permission to.
So far in this class, we've written programs (either in Bash or C)
that have required access to those resources. For example, we've
read user-input through keyboard (device management); we've invoked
and executed programs through bash (process management); we've
allocated and deallocated memory in C using malloc() and
calloc() (memory management); and, we've read, written, and
created files in both C and Bash (file system management).
In each of those cases, while it is nice to think that we, as the programmer, have done these things, in fact, the operating system has performed these actions on our behalf in a supervisory role. This is mostly for our protection and convenience. Would you really want to have to read directly from the keyboard driver in order to get input from the user? Would you want to write to the display driver to print information back? Maybe you do, if you're nuts about computing, but most of us don't. And further, if you do want to perform these low level actions yourself, it's really easy to mess it up, at which point, your computer may be broken forever. For example, if you had to manipulate the filesystem directly, and you made a mistake —oops, you just lost all your files!
1.2 Kernel Space vs. User Space
The kernel of the OS is a program that is trusted to perform all the protected system resource actions. The kernel is trusted software and executes in supervisory mode, and all the basic OS functionality is implemented from with the kernel software. We describe the domain of the kernel as kernel-space. Actions that can be performed without privilege, that is, do not require the kernel, are described as part of the user domain, or user-space.
The distinction between these two domains is important. For
example, adding two numbers together, a process completed by an
add instruction on the processor, is unprivileged and is
performed in user-space. Similarly, the action of iterating through
an array and reading and writing data already allocated in memory
is also unprivileged and performed in user-space. But, the
allocation of new memory, by adjusting the break point, for
example, is a privileged process, and must be completed by the
kernel.
2 System Calls
When a privileged access is required, a context-switch between the user program and the kernel must be performed. A context switch occurs when the user program execution is stopped, the current state is saved and offloaded from the processor, and the kernel is swapped in to complete the protected task. Once the operating system completes the request, the kernel will stage any results to be returned to the user process, and the kernel is swapped out in favor of the user process. Execution continues from that point.
A system call is a function stub that is the entry point for
requesting OS services. So far, we've been using functions that are
defined in the C standard library, stdlib.h, but supporting these
operations are system calls, defined in unistd.h, the unix
standard library. For example, managing memory allocation is the
domain of the operating system, but so far we've just been using
malloc() and calloc() to perform these tasks.
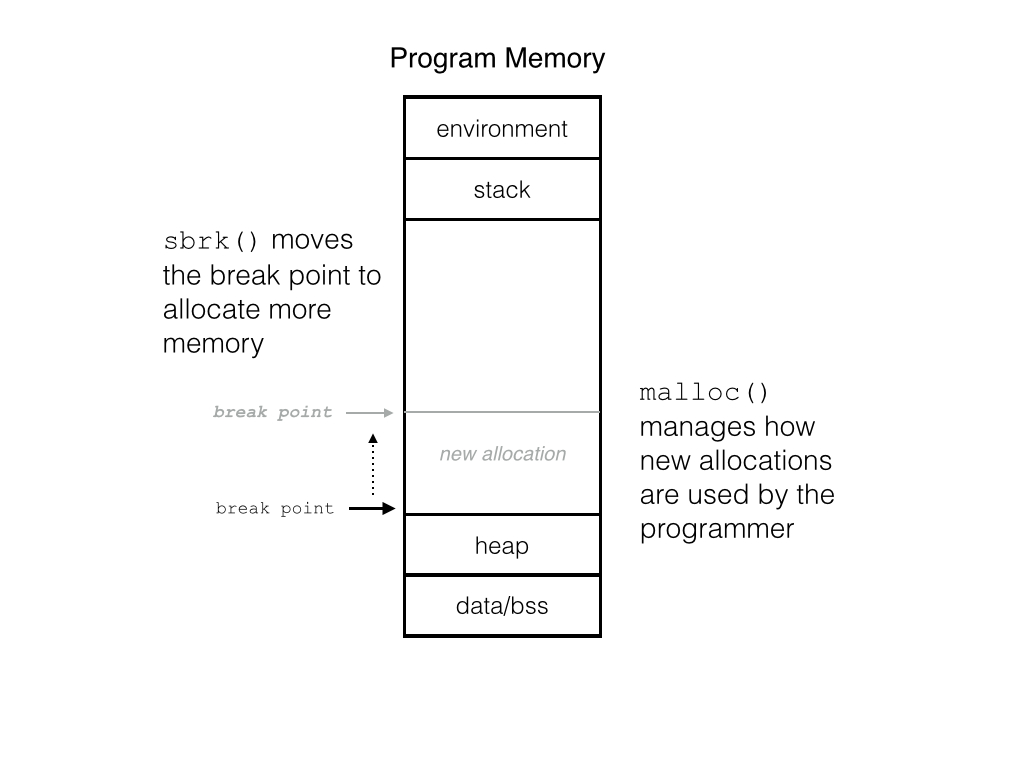
The C memory allocation routine is really about how to manage the
memory that has already been allocated. As programs free and
allocate new memory all the time, malloc() attempts to find
contiguous memory to fulfill those new request. There are many ways
to do this, for example, find the first region of unallocated
space, even if it is too big, and use that (first fit), or the
allocator can look a region of unallocated memory that is as close
to the request size (best fit). Both strategies are fine, but the
operating system is not involved in that process; however, when
there is no more space in the heap, the break point needs to be
adjusted, then the Operating System needs to get involved. The
system call that moves the break point is called sbrk(), and it
is a function from the unix system library. Whenever malloc()
cannot fill an allocation request, it calls sbrk() which adjust
the break point, effectively allocating more memory.
2.1 Kernel Traps
The invocation of the kernel to perform a context switch occurs
through a trap. A trap is a special instruction to the processor
that an operation is needed from the kernel. The processor interrupts
the current execution of the program, saves the state, and invokes
the kernel with the trap information. In the running example, this
will be a trap for the kernel function sys_sbrk() which was
invoked via the system call sbrk().
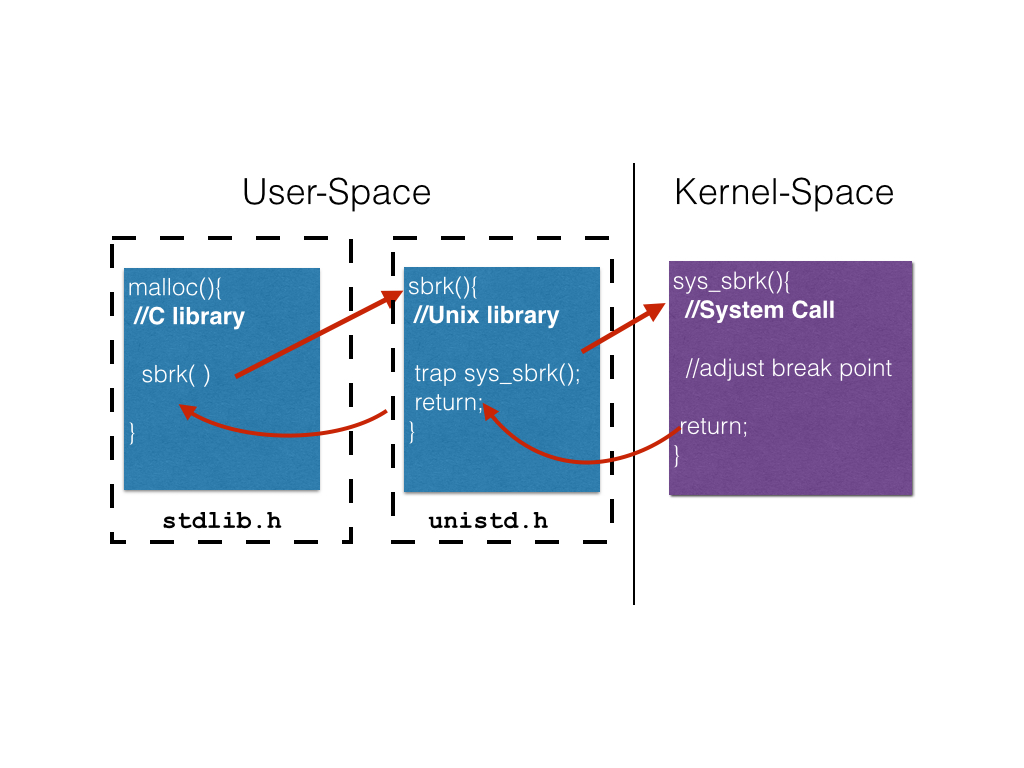
The kernel will then fulfill the request via the kernel function. Once that function returns, the kernel is context switched out, the user process is context switched in, and execution continues as before.
2.2 How to recognize a system calls using the man pages
So far in this class we haven't been using the system call interface directly, but rather we have used the C standard library to interface for us. This is going to change as we explore the Unix system, and it is important that you can identify the differences between library functions and system calls.
The easiest way to do this is via the manuals. The man pages are divided into sections to better organize the plethora of manuals available. There is a total of 8 sections, and below are the relevant ones.
- Section 1: General commands, such as those found in the bash environment
- Section 2: System calls, such as
sbrk() - Section 3: Library functions, such as
malloc() - Section 8: System Administration, … get to that later
For example, if we type, man malloc, and inspect the header of
the manual, we can learn a lot of information:
MALLOC(3) Linux Programmer's Manual MALLOC(3)
NAME
malloc, free, calloc, realloc - Allocate and free dynamic memory
SYNOPSIS
#include <stdlib.h>
void *malloc(size_t size);
void free(void *ptr);
First we can see that malloc() is in section 3 of the manual via
MALLOC(3) header. Also, from the synopsis, we see that it is a
part of the C standard library via the #include <stdlib.h>. As a
comparison, let's look at the manual for sbrk().
BRK(2) Linux Programmer's Manual BRK(2)
NAME
brk, sbrk - change data segment size
SYNOPSIS
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
The sbrk() command, with brk(), is in section 2 of the manual
via the BRK(2) header, and it also in the unix standard library,
which we know from #include <unistd.h>.
One problem you may encounter is that there are manuals that have
the same name. For example, there is the read command for bash,
which is a general command in section 1 of the manual, and there is
also the system call read(), which is in section 2 of the
manual. The preference for the man command is to always retrieve
lower numbered manuals. For example,
man 2 read
will display the bash read command and not the system call
read(). To access the system call manual for read(), use
#> man 2 read
READ(2) Linux Programmer's Manual READ(2)
NAME
read - read from a file descriptor
SYNOPSIS
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
3 Tracing a Library and System Calls
Another method for identifying understanding how programs using
system calls or library calls is to look trace the program using
ltrace and strace. These two programs monitor execution and
report either the library calls used or the system calls,
respectively.
3.1 Library Call Tracing
To begin, let's look at a simple program that prints "Hello World"
int main(){ char hello[]= "Hello World!"; puts(hello); }
This program is not very complicated. It defines a string called
hello that references the string "Hello World." The string is
then outputted using puts() which puts the string to standard
out, like printf(), but since we are not doing any formatting, we
use the simpler output method.
We can compile and execute the program like before:
user@ic221-unix$ gcc helloworld.c -o helloworld user@ic221-unix$ ./helloworld Hello, World!
What we would like to do now is trace this program to see what
library calls are used during execution. We can do this with
ltrace, and we redirect the output so it doesn't interfere with
the output of the ltrace
user@ic221-unix$ ltrace ./helloworld > /dev/null
__libc_start_main(0x400596, 1, 0x7ffea979c798, 0x4005f0 <unfinished ...>
puts("Hello, World!") = 14
+++ exited (status 0) +++
And we can clearly see that, yes, indeed this program calls
puts(). This is a library function. We could also look at
malloc like our previous examples and see the library functions,
like in the program below:
typedef struct{ int a; int b; } pair_t; int main(){ pair_t * pair = malloc(sizeof(pair_t)); pair->a=10; pair->b=20; printf("(%d,%d)\n", pair->a,pair->b); }
Here's the output normally and with ltrace:
user@ic221-unix$ ./pair
(10,20)
user@ic221-unix$ ltrace ./pair > /dev/null
__libc_start_main(0x400566, 1, 0x7ffcea276338, 0x4005c0 <unfinished ...>
malloc(8) = 0x2411010
printf("(%d,%d)\n", 10, 20) = 8
+++ exited (status 0) +++
user@ic221-unix$
This time there are two library methods called, and these are ones that match the program. But there is actually more going on.
3.2 Looking at Library System calls with ltrace
If were to add the -S flag to ltrace we get a bit different
narrative of our program. The -n flag says to indent nested
function calls so we can more clearly see the process of the
program.
user@ic221-unix$ ltrace -S -n 3 ./helloworld > /dev/null
SYS_brk(0) = 0x11e8000
SYS_access("/etc/ld.so.nohwcap", 00) = -2
SYS_mmap(0, 8192, 3, 34) = 0x7f3877a78000
SYS_access("/etc/ld.so.preload", 04) = -2
SYS_open("/etc/ld.so.cache", 524288, 01) = 3
SYS_fstat(3, 0x7ffd9b688060) = 0
SYS_mmap(0, 0x614c, 1, 2) = 0x7f3877a71000
SYS_close(3) = 0
SYS_access("/etc/ld.so.nohwcap", 00) = -2
SYS_open("/lib/x86_64-linux-gnu/libc.so.6", 524288, 016751740550) = 3
SYS_read(3, "\177ELF\002\001\001\003", 832) = 832
SYS_fstat(3, 0x7ffd9b6880b0) = 0
SYS_mmap(0, 0x3c8a00, 5, 2050) = 0x7f387748c000
SYS_mprotect(0x7f387764c000, 2093056, 0) = 0
SYS_mmap(0x7f387784b000, 0x6000, 3, 2066) = 0x7f387784b000
SYS_mmap(0x7f3877851000, 0x3a00, 3, 50) = 0x7f3877851000
SYS_close(3) = 0
SYS_mmap(0, 4096, 3, 34) = 0x7f3877a70000
SYS_mmap(0, 4096, 3, 34) = 0x7f3877a6f000
SYS_mmap(0, 4096, 3, 34) = 0x7f3877a6e000
SYS_arch_prctl(4098, 0x7f3877a6f700, 3, 34) = 0
SYS_mprotect(0x7f387784b000, 16384, 1) = 0
SYS_mprotect(0x600000, 4096, 1) = 0
SYS_mprotect(0x7f3877a7a000, 4096, 1) = 0
SYS_munmap(0x7f3877a71000, 24908) = 0
__libc_start_main(0x400596, 1, 0x7ffd9b688a48, 0x4005f0 <unfinished ...>
puts("Hello, World!" <unfinished ...>
SYS_fstat(1, 0x7ffd9b6887f0) = 0
SYS_ioctl(1, 0x5401, 0x7ffd9b688760, 404) = -25
SYS_brk(0) = 0x11e8000
SYS_brk(0x120a000) = 0x120a000
<... puts resumed> ) = 14
SYS_write(1, "Hello, World!\n", 14) = 14
SYS_exit_group(0 <no return ...>
+++ exited (status 0) +++
Notice that this time there is a lot, lot more going on. In
particular, there is a number of calls that occur before the main
part of our program even gets started at the call to
__libc_start_main().
The second thing to notice is everything under main(), which we
can duplicate below:
__libc_start_main(0x400596, 1, 0x7ffd9b688a48, 0x4005f0 <unfinished ...>
puts("Hello, World!" <unfinished ...>
SYS_fstat(1, 0x7ffd9b6887f0) = 0
SYS_ioctl(1, 0x5401, 0x7ffd9b688760, 404) = -25
SYS_brk(0) = 0x11e8000
SYS_brk(0x120a000) = 0x120a000
<... puts resumed> ) = 14
SYS_write(1, "Hello, World!\n", 14) = 14
SYS_exit_group(0 <no return ...>
+++ exited (status 0) +++
Shows what really happens after we call puts(). There is a bunch
of SYS_* calls. What are these? This is a library function in C
to make a system call. We can actually call it directly ourselves
to make a system call.
3.3 Making a System Call with syscall()
C provides a direct way to make a system call in C without going
through other library methods: syscall(). The syscall()
interface is the following:
.--- System Call Number
v
syscall(long number, ...)
^
'---- Remaining Arguments to the system call
The first argument, the system call number, is a way to specify which system call you want to call. Each system call has a unique number assigned to it and it is machine code and operating system dependent. For example, in x86 (32-bit), write is system call number 4, but in x8664 (64-bit) write is system call number 1.
As we are working on 64-but machines in the lab, let's rewrite our
program to use syscall() to write hello world.
#include <unistd.h> int main(){ char hello[] = "Hello, World!\n"; // .-- System call number for write() // v syscall(1, 1, hello, 14); // \__________/ // | // '-- arguments to write() system call // 1: for stdout // hello: string to write // 14: the length of the string to write }
Note that the arguments following the system call number match the
arguments to the write() system call, which we learned from doing
the ltrace above. Now we can run this program to see the output
and do another trace of it (focusing only on the output for main()):
user@ic221-unix$ ./syscall
Hello, World!
user@ic221-unix$ ltrace -S -n 3 ./syscall > /dev/null
(...)
__libc_start_main(0x400596, 1, 0x7ffd2a7fce18, 0x400610 <unfinished ...>
syscall(1, 1, 0x7ffd2a7fcd10, 14 <unfinished ...>
SYS_write(1, "Hello, World!\n", 14) = 14
<... syscall resumed> ) = 14
SYS_exit_group(0 <no return ...>
+++ exited (status 0) +++
Perfect, we get the same otuput, but we are still seeing that we
are actually calling SYS_write() via a library interface. We are
still not really calling the system call directly.
3.4 Write hello world without library calls
The only way to directly invoke a system call is by writing our
program not in C, but rather in the programming language that C is
compiled into, binary. The language of binary programs on most
64-bit unix machines is x8664. We will use asm style syntax to
write a hello world program, and let's see what a hello world
program would look like:
SECTION .data
;;char hello[] = "Hello, World!\n"
hello db "Hello, World!",0x0a
SECTION .text
global _start
_start:
;;syscall(1,1,hello,14)
mov rax,1
mov rdi,1
mov rsi,hello
mov rdx,14
syscall
;;syscall(60,0); //exit with status 0
mov rax,60
mov rdi,0
syscall
The mov commands are assignment, and putting values in
registers that match the arguments to syscall. We also added an
extra system call to exit the program cleaning. Compiling and
running this program looks a bit different, but the result is the
same.
user@ic221-unix$ nasm -f elf64 helloworld.asm user@ic221-unix$ ld helloworld.o -o helloworld user@ic221-unix$ ./helloworld Hello, World!
What is interesting now, is that if you were to ltrace this
program, you get nothing!
user@ic221-unix$ ltrace -S -n 3 ./helloworld > /dev/null Couldn't find .dynsym or .dynstr in "/proc/292/exe"
That's because we are no longer using the C library at all, we are
now using the system call interface in its purest form. To see what
is happening, we need to use strace, the system call tracing
user@ic221-unix$ strace ./helloworld > /dev/null
execve("./helloworld", ["./helloworld"], [/* 16 vars */]) = 0
write(1, "Hello, World!\n", 14) = 14
exit(0) = ?
+++ exited with 0 +++
When you do that, you see that, yes, in fact we are still doing a
write(). We are also seeing the execve() system call, which is
the system call that starts the execution. This in a sense, is a
simple as it gets and as close to the operating system we will go.
4 Device IO via System Calls
4.1 System Calls, File Management and Device I/O
In the last lesson, we identified the system resources that the OS is responsible for managing. These include:
- Device Management : Hardware devices, such as keyboard, monitors, printers, hard drives, etc., are resources managed by the computer. When a programmer wishes to interact with these devices, a unified interface provided by the OS is used.
- Process Management : The invocation and execution of a program, a process, is managed by the OS, including managing its current state, running or stopped, as well as the loading of code.
- Memory Management : The access to physical and virotual memory is controlled by the OS, and a programs memory layout and current allocations is carefully managed.
- File System Management : The OS is also responsible for ensuring that programs can read and write from the filesystem, but also that programs don't corrupt the file sysystem or access files/directory that they do not have permission to.
The major theme of this course is understanding the OS System Call
API that the Unix system uses to access these resources. So far,
we've been using the system call API via the C standard library, but
underneath the covers, system calls were being used. As an example of
the difference between a system call and a library lesson, in the
last lesson, we identified that the memory management functions ,
malloc() and calloc(), is actually a standard library
function. Real memory allocation occurs via the system call sbrk(),
which adjust the break point to increase the size of the heap.
In today's lesson, we are going to do the same for the Device
Management and File System Management resources. In previous lessons,
we have interacted with the file system and performed I/O via the
file stream interface, FILE *, and used standard I/O library
functions like, fprintf() and fputc() and etc. The file stream
interface is a lot like malloc(), it is a nice library feature that
provides a service; under the file stream interface lies the system
calls that help manage file opening and closing as well as reading
and writing from files. We are going to go back to first principles,
let's do Hello World again!
4.2 Hello World (again)
From now on, let's assume that we don't have the C standard library,
or the C standard I/O library: How do we write our Hello World
program? We need to use a lower level function, a system call, to
write directly to the standard out device, i.e., the terminal
window. The system call that writes to a file or device is
write(). Bellow, is a the system call hello world:
#include <unistd.h> int main(int argc, char * argv[]){ char hello[] = "Hello World\n"; char *p; for(p = hello ; *p ; p++){ write(1, p, 1); } }
Much of this program should be familiar to you. We assign the "Hello
World" string to the array hello, and we then iterate over that
array one character at a time using pointer arithmetic until the
end. The output is via the write() system call, but the specifics
of that system call, as well as the complimentary system call,
read(), need further explanation.
4.3 Basics of write() to terminal
Both the read() and write() system calls operate over file
descriptors rather than file streams, and read from or write to
buffers not strings. A file descriptor is just an integer, a
number, that refers to a currently open file. The OS uses the file
descriptor number as an index into the file descriptor table of
currently open files to gain access to the actual device the I/O
operations should be performed, like a file on disk, or writing to
the terminal, or reading data from the network controller. (We
discuss file descriptors more in the next section.)
While you might not know how to open new files yet as a file descriptor, we still have the standard input/output/error streams to work with. Finally, we can use standard descriptor numbers:
- Standard Input : 0 :
STDIN_FILENO - Standard Output : 1 :
STDOUT_FILENO - Standard Error : 2 :
STDERR_FILENO
You should note that the file descriptor numbers are the same as
the numbers we used for bash programming and redirects …
everything is connected. Also, unistd.h provides three constants
to refer to the standard file descriptors, STIDN_FILENO,
STDOUT_FILENO, and STDERR_FILENO, which can help improve the
readbility of your code.
We can now start to piece together the write() command from above
a bit more:
// .-- Write to standard out, file descriptor 1 // v write(1, p, 1); // ^ ^ // | '--- Number of bytes to write, just the char p points to // | // '-------- char *, points to the byte we want to write
The first argument to write() is the file descriptor of where we
are writing. In this case, we are programming "Hello World", so we
want to print to standard out, or file descriptor 1. The next
argument is a bit more obvious, p points to a char we want to
write, and the last argument is the number of bytes we want to
write. Go through the "Hello World" program from top to bottom, we
can now see that it just prints each character of the hello string
to standard out, one at a time, until the NULL terminator is
reached.
Now that we know how to write a string to the terminal using the
system call write() without library functions, it's fun to tilt
your head a bit and think for a minute about how just this little
bit of code, just the write() system call, can be used to program
all the file output we've learned so far. How might we program
fputc() or printf()? I'm sure you could, but thankfully, we
don't have to because someone did it for us in the standard library.
4.4 read() and write() in Detail
4.4.1 write()'ing a Buffer of Bytes
The above example was working with one byte at a time, but system
call I/O is buffered. The write() and read() system calls are
not string based I/O, like the format print functions. They will
read and write any data type. Let's look at bit more at the actual
function prototype form the man page:
ssize_t write(int fd, const void *buf, size_t count); // ^ ^ ^ //file descriptor---' buffer--' '-- num. bytes to write
Note that the second argument is not a char *, but rather a void
*, which means that it accepts a pointer to any type. We refer to
this as the buffer. A buffer is the general term for an array of
bytes. Unlike a string, which is also an array of bytes, as
char's, strings have the added property of always being NULL
terminated. Buffers are more low-level, and can refer to any data
type. As we learned in previous lessons, pointers and arrays are
the same thing and that we can arbitrarily cast between different
pointer types. This allows us to arbitrarily cast any data type to
a byte array, a buffer, and work with the data
byte-by-byte. Consider the example below, where we write a
pair_t.
/*write_pair.c*/ #include <unistd.h> typedef struct{ int left; int right; } pair_t; int main(int argc, char * argv[]){ pair_t p; p.left = 10; p.right = 20; write(1, &p, sizeof(pair_t)); return 0; }
Now, this bit of code probably wouldn't give us terminal output
that make sense to us humans because we are not writing strings. It
will not print "10" or "20", and that's because write() is writes
raw bytes. The data that is the pair is not ascii, and its
individual bytes will not render like normal ascii characters. The
temrinal does not understand how to render aribtrary bytes that are
not unicode or ascii, and as a result, nothing gets dispalyed. But,
the bytes are definitely getting written, and we can see that by
read()'ing those bytes.
4.4.2 read()'ing a Buffer of Bytes
The read() command is exactly the same as the write() command,
but in reverse. Data is read from the descriptor and written into
the buffer. Here is the function prototype from the man page:
ssize_t read(int fd, void *buf, size_t count); // ^ ^ ^ //file descriptor---' buffer--' '-- num. bytes to write
Again, the concept of a buffer as just an array of bytes is
important. read() will attempt to read up to count number of
bytes and store them into the buffer. The total number of bytes
read is returned. This is important so that you know how many bytes
made it into the buffer. If EOF is reached, read() returns 0.
To demonstrate the connection between read()'ing and
write()'ing raw bytes, let's continue the example from above.
Suppose we are interested in reading in the raw bytes of a
pair_t. We can do the following:
/*read_pair.c*/ #include <unistd.h> #include <stdio.h> //format print typedef struct{ int left; int right; } pair_t; int main(int argc, char * argv[]){ pair_t p; read(0, &p, sizeof(pair_t)); printf("left: %d right: %d\n",p.left, p.right); return 0; }
Note that the read() is reading from file descriptor 0, which is
standard input, and the buffer is the address of the p, reading at
most the size of a pair_t. The read() command is just reading
byte-by-byte the data that is the pair_t and filling up the memory
region of p with those bytes. It might be a bit mystifying, but
this actually works, and we can test it by aligning the two programs
in a pipeline.
#>./write_pair | ./read_pair left: 10 right: 20
The write_pair program writes the raw bytes of a pair to standard
output which is piped to the standard input of the read_pair
program. read_pair then fills the buffer, that is the pair, with
those bytes, and finally, we can print them out to the screen. In
the parlance of system programming, "we're just shoveling bits
around".
5 File IO via System Calls
The last piece of the I/O puzzle is reading and writing from
files. Previously, we've been using the fopen() and fclose()
system call which returns a file stream, that is a FILE *. It
works really well and is very easy to use, but these are C library
functions which really use system calls. You know this because the
OS is responsible for managing device I/O resources, such as reading
and writing from keyboards, disks, etc, and the OS is also
responsible for managing the file system, such as keeping track of
files, directories, and paths. Both of those resources come into
play when opening a file and reading and writing from that file.
5.1 File descriptors
The system call to open a file is open(), which is well named,
and the system call to close a file is close(), also well
named. These system calls are low level and do operate over file
streams, as FILE *, but instead return an integer value which is
the file descriptor.
All open files in the operating system are managed via file descriptors, which are indexes into the file descriptor table. The file descriptor table is a kernel data structure which tracks open files for all programs, and we'll discuss the details of this in a later lesson. For the purposes of today, the key concept is that we reference open files via an integer value, the file descriptor.
As previously discussed, each program comes ready made with three open file descriptors, the standard file descriptors. Each has an assigned number: 0, stdin; 1, stdout; and, 2 stderr. When you open a file, it will be assigned the next lowest file descriptor number available, which might be 3 for the first file, and then 4, and so on.
5.2 open()'ing a File Descriptor
To open a file we use the open() system call is define in the
file control librar, fcntl.h, and the function prototype is as
follows:
int open(const char *path, int oflag, ... /*mode_t mode*/ );
There is either two or three arguments to open(). In the simple
case, where we are not creating a file, open() only takes two
arguments, but if a file is created, we need to specify the
permission mode of that file, such ad read/write/exec.
Conceptually, open(), is a lot like fopen() in the simple case
when you are opening a file for reading.
int fd = open("path/to/file", O_RDONLY);
The oflag argument is a lot like the mode from fopen(), but
instead of using a string we use integer (and binary-combinations
thereof) to indicate the desired open condition. Fortunately, these
values are defined constants for us, so we don't have to combine
integer flags ourselves. In the above example, the file at the
given path is opened for reading, only, with O_RDONLY flag.
If we wanted to open a file for writing, truncate the file if it exists or create it if it does not exist, then we need to combine some flags and specify a mode. Here is an example:
int fd = open("test.txt", O_WRONLY | O_TRUNC | O_CREAT, 0664);
The second argument O_WRONLY | O_TRUNC | O_CREAT is often called
an ORing, and refers to a set of options that are combined using
the bit-wise OR operator. The way this works is that each option
sets a bit in a field, in this case, one bit in the integer. The
bitwise or, will result in the accumulation of all the set bits.
00000000000000000000000000000001 O_WRONLY 00000000000000000000010000000000 O_TRUNC 00000000000000000000001000000000 O_CREAT --------------------------------- OR 00000000000000000000011000000001 O_WRONLY | O_TRUNC | O_CREAT
Here are the relevant option flags for opening a file:
O_RDONLYopen for reading onlyO_WRONLYopen for writing onlyO_RDWRopen for reading and writingO_APPENDappend on each writeO_CREATcreate file if it does not existO_TRUNCtruncate size to 0
The mode portion of the arguments, 0664, is an octet, just like we
use for chmod in has. The leading 0 is indicator that the
following values are in octal, not base 10.
There are also settings shortcuts to reference different mode settings to use in an ORING
S_IRUSR00400 owner has read permissionS_IWUSR00200 owner has write permissionS_IXUSR00100 owner has execute permissionS_IRGRP00040 group has read permissionS_IWGRP00020 group has write permissionS_IXGRP00010 group has execute permissionS_IROTH00004 others have read permissionS_IWOTH00002 others have write permissionS_IXOTH00001 others have execute permission
So 0644 is equivalent to the ORING:
S_IRUSR | S_IWUSER | S_IRGRP | S_IWGRP | S_IROTH
We since writing modes in octal is relatively straight forward (and less typing), we will switch between these two settings during the semester.
5.3 User Masks for File Creation
The last aspect of opening and creating files is the user mask, or
umask. This is a mechanism to specify which permissions of newly
created files should be turned off by default, and functions as a
security parameter for the system.
The umask is specified as a mode in octal, just like above,
except it is inverted. The bits that are set to one indicate that
those permissions should be turned off by default. We can see the
current umask of the system using the shell command:
aviv@saddleback: part2 $ umask 0027
The umask of 0027 specifies that files that are initially created should have all other read, write, and execute off and group execute off, but all other permissions should be allowable.
The way this is enforced, is when open() creates a new file it
sets the permissions to:
mode & ~umask
The & and ~ symbols are bitwise operators for AND (&) and NOT
(). The NOT operator () on bits will invert all the bits, so ones
becomes zeros and zeros ones. And the AND operator (&) is a checks
if both values are true.
So for the file creation with permission mode 0644 and mask
0027, we get the final creation permissoin:
0664 & ~(0027) = 0664 & 0750 = 0640
Following the math, the inverse of 0027 in binary is,
~ 000 -> 111 = 7 = 7-0 ~ 010 -> 101 = 5 = 7-2 ~ 111 -> 000 = 0 = 7-7
Because inverse flips all the bits, it is the same as subtracting the value from 7. With the inverse complete, we can now do the bitwise AND of 0750 and 0644 is:
101 101 000 & 111 100 000 -------------- 110 100 000 = 640
The mask ensures that we don't create a file with more permissions than we want. In this example, with this umask, we removed the possibility of writing from the group and read,write, execute from everyone else.
5.4 close()'ing a File
Finally, to close the file descriptor you use the close() system call, which
is defined in unistd.h. It has the following function prototype:
int close(int filde)
All open file descriptors should be closed whenever they are no longer needed. Once a program exists, the file descriptors are closed automatically.