Lec 18: File Duplication and Pipes
Table of Contents
1 Resource Duplication Across Forks
Recall, from our discussion of fork() and process duplication, the
entire process is duplicated, not just the code, but also all the
state of the process. This includes the entire state of memory, such
as the values of variables. For example, consider the program below
that will fork 5 children tracked with a variable i, which is
printed from the child, then manipulated in the child, and printed
again in the parent.
int main(int argc, char * argv[]){ int status; pid_t cpid, pid; int i=0; while(1){ //loop and fork children cpid = fork(); if( cpid == 0 ){ /* CHILD */ pid = getpid(); printf("Child: %d: i:%d\n", pid, i); //set i in child to something differnt i *= 3; printf("Child: %d: i:%d\n", pid, i); _exit(0); //NO FORK BOMB!!! }else if ( cpid > 0){ /* PARENT */ //wait for child wait(&status); //print i after waiting printf("Parent: i:%d\n", i); i++; if (i > 5){ break; //break loop after 5 iterations } }else{ /* ERROR */ perror("fork"); return 1; } //pretty print printf("--------------------\n"); } return 0; }
And we can see the output of this program
>./shared_variables Child: 3833: i:0 Child: 3833: i:0 Parent: i:0 -------------------- Child: 3834: i:1 Child: 3834: i:3 Parent: i:1 -------------------- Child: 3835: i:2 Child: 3835: i:6 Parent: i:2 -------------------- Child: 3836: i:3 Child: 3836: i:9 Parent: i:3 -------------------- Child: 3837: i:4 Child: 3837: i:12 Parent: i:4 -------------------- Child: 3838: i:5 Child: 3838: i:15 Parent: i:5
Looking through the output, we can see each of the 5 children
identified by their process id, and we can track the state of the
variable i. It is initialized in the parent prior to the fork, and
that value is duplicated to the child, as indicated by the first
child print. The child then multiplies i by 3, and prints the
value again, which is indicated by the second child
print. Meanwhile, the parent is waiting for the child to terminate
with a call to wait(), and then prints its own view of the
variable i, which is unchanged.
The program demonstrates how duplication occurs across a fork. The current state of the parent is duplicated to the child, but additional edits by the child are on its own version of the memory not the parents, which also has its own version of the memory.
1.1 File Descriptor's across Forks
All values duplicate in a process are duplicated across a fork, which brings up some interesting situations, like what happens when the process has open file descriptors. For example:
int fd = open( .... ); cpid = fork(); if( cpid == 0){ /*CHILD*/ //reading from same file as parent? read(fd, ....) }else if (cpid > 0){ /*PARENT*/ //reading from same file as child? read(fd, ....) }
First, consider that the reference to an open file, a file
descriptor, is just an integer number (fd above) that is used by
the operating system to look up the open file in the file
descriptor table. The entry in the table contains a number of
information, including what point in the file is currently being
referenced. For example, if you read 10 bytes from a file
descriptor, and then some point in later in the program read 10
bytes again, you do not reread the same 10 bytes, instead you read
the next 10 bytes. This is accomplished via the data stored in the
file descriptor table which tracks the current place in the file.
Returning to the example above, the value of fd should be
duplicated from parent to child. The question is, how does this
affect the data stored in the file descriptor table. Technically,
the value of fd, e.g., a number like 3, is the same for parent and
child, and should then reference the same entry in the file
descriptor table, and it does. Interestingly, it not only references
the same entry in the table, but that there is nothing wrong with
two differences processes reading from the same file, which will
stay in sync.
You can see this in the program below where a parent and child process alternate between reading 1 byte at a time from a file.
int main(int argc, char * argv[]){ int fd, status; pid_t cpid; char c; if ( argc < 2){ fprintf(stderr, "ERROR: Require path\n"); return 1; } //shared between all children and parent if( (fd = open(argv[1], O_RDONLY)) < 0){ perror("open"); return 1; } while (1){ cpid = fork(); if( cpid == 0 ){ /* CHILD */ //try and read 1 byte from file if( read(fd, &c, 1) > 0){ printf("c: %c\n", c); // print the char _exit(0); //exit with status 0 on sucess read }else{ //no more to read _exit(1); //exit with status 1 on failed read } }else if ( cpid > 0){ /* PARENT */ //wait for child to read first wait(&status); //if exit status 1, break the loop, no more to read if( WEXITSTATUS(status) ){ break; } //now parent reads a byte if( read(fd, &c, 1) > 0){ printf("p: %c\n", c); // print the char } }else{ /* ERROR */ perror("fork"); return 1; } } //done reading the file close(fd); return 0; }
Prior to entering the loop, a file is open, and after each fork, the file descriptor is duplicated to the child, which tries to read a byte and print it, returning either success or failure if there is no more bytes to read. Meanwhile, the parent is waiting for the child terminate, checks the status, and if there is more of the file to read, the parent then reads and prints a byte. The result is that the program alternates between reading 1 byte at a time from a file between parent and a sequence of children. Here's the output of running the program, "c:" is a print from a child and "p:" is a print from the parent.
#> cat helloworld.txt Hello World! #> ./shared_files helloworld.txt c: H p: e c: l p: l c: o p: c: W p: o c: r p: l c: d p: ! c:
2 Inter-Process Communication and Pipes
Where duplication of file descriptors becomes interesting is when you consider the possibility for inter-process communication. So far, we've seen very limited inter-process communication through the setting of exit status or termination conditions; a parent can check the status of a terminating child and perform some action based on that. But, how can a child communicate to a parent? Or, how can we communicate more than just a short number?
We know that process can communicate a large amount of information over a text stream with a pipe on the command line, and, moreover, this is vital part of the Unix design philosophy. What we are going to look at now is how we can create pipes to perform inter process communicating, leveraging the duplication of file descriptors across forks.
2.1 Hello pipe()
The pipe() system call is used to create a set of connected file
descriptors, one for reading and one for writing. Whatever data is
written to the write end of the pipe can be read from the read end
of the pipe. Here's the generally setup:
int pfd[2]; //pfd[0] reading end of pipe //pfd[1] writing end of pipe //open the pipe if( pipe(pfd) < 0){ perror("pipe"); return 1; }
Now pfd and array of two integers for file descriptors is set
such that pfd[0] is the reading end (like 0 for stdin) and
pfd[1] is the writing end (like 1 for stdout). We can now use the
two file descriptors to transfer data. For example, here is the
hello-world program for pipes:
int main(int argc, char * argv[]){ //print hello world through a pipe! char hello[] = "Hello World!\n"; char c; int pfd[2]; //pfd[0] reading end of pipe //pfd[1] writing end of pipe //open the pipe if( pipe(pfd) < 0){ perror("pipe"); return 1; } //write hello world to pipe write(pfd[1], hello, strlen(hello)); //close write end of pipe close(pfd[1]); //read hello world from pipe, write to stdout while( read(pfd[0], &c, 1)){ write(1, &c, 1); } //close the read end of the pipe close(pfd[0]); return 0; }
The program writes "Hello World!\n" to the write end of the pipe, and then reads it back from read end of the pipe, writing the result to stdout.
2.2 Pipes Bursting! and Blocking!
There are a number of very reasonable questions you should be asking at this point:
- Where does the data go that's written to the pipe? It must be stored somewhere because we read it back later.
- How much data can we write to the pipe before we have to read it? Computers are finite machines, at some point, the pipe must burst!
To answer the first question, where does the data go, we can refer back to our discussions of I/O buffering. We know that the O.S. and the C standard library provides some amount of buffering on reads and writes. From the perspective of the program, it sees a pipe file descriptor like any other file descriptor, but instead of being hooked into a file in the file system, it actually points to a buffer, a storage space, in the kernel. Reading and writing from the pipe is just a matter of adding data to the buffer and remove data from the buffer.
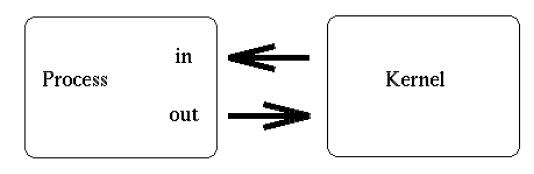
Figure 1: In and Out of a pipe communicate through the kernel (source tldp.org)
To answer the second question, how much data, we can write a program and find out. Below, here is a program that opens a pipe, and writes 'A' to the pipe in an loop, which will break when the write fails. It also maintains a count of how many times 'A' was written.
int main(int argc, char * argv[]){ char c = 'A'; int i; int pfd[2]; //pfd[0] reading end of pipe //pdf[1] writing end of pipe //open the pipe if( pipe(pfd) < 0){ perror("pipe"); return 1; } //write A's to pipe until it's full i = 0; while( write(pfd[1], &c, 1) > 0){ printf("%d\n",i); i++; } perror("write"); //close write end of pipe close(pfd[1]); //read from pipe?!? while( read(pfd[0], &c, 1)){ write(1, &c, 1); } close(pfd[0]); return 0; }
Before we give the output, let's consider some possibilities. Two come to mind.
- First, we'll write as many 'A's as possible counting and printing
all along, and then the
write()will fail, -1 is returned. The result is the count and that many A's. Essentially, once the pipe is full, a write fails. - Another possibilities is that once the pipe is full, and you try and do that last write, it doesn't fail, it just makes the program wait until the pipe is no longer full, that is, another program has read from it. Essentially, once the pipe is full, the write blocks.
Two possibilities, what happens? We don't need to squint, we can run the program, and here's the output.
#>./pipe_block 1 2 (...) 65534 65535 ^C
It's number 2: when the pipe is full, the write will block. We can
see this because the program printed all the numbers and the it
reached a max, hung, and was terminated with Ctrl-c. The number
65535 is also meaningful, it is 216 -1, which is as good a choice
for the pipe size.
However, it could have been number 1, a failed write. The Operating
System allows you to change the way read/write call function
depending on the file descriptor. The way to do this is using the
fcntl() or file descriptor control. This system call allows you
to set a number of options (or flags) about the interaction with a
file descriptor. One such flag is an option to set the file
descriptor to be non-blocking:
//set pipe to not block fcntl(pfd[1], F_SETFL, O_NONBLOCK);
You can read more about other flags in the man pages man 2 fcntl,
but the above call just sets the write end of the pipe to be
non-blocking. If we rerun the program with that setting:
#>./pipe_nonblock 1 2 (...) 65534 65535 write: Resource temporarily unavailable AAAAAAAAAAAAAAAAAAAAAAA (...)
The write() will fail with a resource unavailable error, the pipe
is full, and then the rest of the program can proceed, printing an
absurd number of 'A's.
2.3 Inter Process Pipes
We now have a pretty good understanding of a pipe, so let's see how to use them to do inter-process communication. Like before, we are going to leverage the fact that after a fork, the process is fully duplicated, which would include the pipe. With the pipe file descriptors in the parent and child, it becomes fairly intuitive to read and write data between them. Here's a really simple program that will send data from the parent to the child across a pipe, and then the child will write what it read to stdout.
int main(int argc, char * argv[]){ //print hello world through a pipe! To child! char hello[] = "Hello World!\n"; char c; int pfd[2]; //pfd[0] reading end of pipe //pfd[1] writing end of pipe pid_t cpid; int status; //open a pipe, pfd[0] for reading, pfd[1] for writing if ( pipe(pfd) < 0){ perror("pipe"); return 1; } cpid = fork(); if( cpid == 0 ){ /* CHILD */ //close the writing end in child close(pfd[1]); //try and read 1 byte from pipe, write byte stdout while( read(pfd[0], &c, 1) > 0){ write(1, &c,1); } //close pipe close(pfd[0]); _exit(0); }else if ( cpid > 0){ /* PARENT */ //close reading end in parent close(pfd[0]); //write hello world to pipe write(pfd[1], hello, strlen(hello)); //close the pipe close(pfd[1]); //wait for child wait(&status); }else{ /* ERROR */ perror("fork"); return 1; } return 0; }
The program is just like the hello_pipe program, but this time,
the parent writes "Hello World\n" to the pipe, but it's the child
that reads it out and writes it to standard output. While this is a
silly example, it is easy to start to see how pipe's can be sued to
communicate across process.
3 Duplicating File Descriptor and Pipelines
The other place we've seen pipes is in the context of bash command lines.
cat sample_db.csv | cut -d "," -f 5 | sort | uniq | wc -l
As we know, he pipe symbol says, connect the standard output of one
program with the standard input of another. From the context of the
pipe() system call, we can begin to imagine how that might be
done, but there's a piece missing. With the pipe() system call, we
get the input and output file descriptors which are used for inter
process communication, but for the commands above, they read and
write from stdout and stdin directly. How do we make them use the
pipe instead? This is accomplished by file descriptor duplication, a
process that overwrites a file descriptor with another, and this can
be done with the standard file descriptors.
3.1 Duplicating a File Descriptor
The system call to duplicate file descriptors is dup(), but we
will use the slightly easier to manage dup2() version of the
system call. Here is the prototype for dup2():
int dup2(int filedes, int filedes2);
It will duplicate the file descriptor fildes onto the file
descriptor filedes2; essentially, if you were to read and write
from fildes2 now, it would be the same as reading and writing
from filedes. The two file descriptors do not have the same
value, one might be 4 and other 7, but their entries in the file
descriptor table has been duplicated.
To see this in action, let's look at a hello world program of file duplication:
int main(int argc, char * argv[]){ //print hello world to a file with dup int fd; //check args if ( argc < 2){ fprintf(stderr, "ERROR: Require destination path\n"); return 1; } //open destination file if( (fd = open(argv[1], O_WRONLY | O_TRUNC | O_CREAT , 0644)) < 0){ perror("open"); return 1; } //close standard out close(1); //duplicate fd to stdout dup2(fd, 1); //print to stdout, which is now duplicated to fd printf("Hello World!\n"); return 0; }
In this program, we open a new file at the file descriptor fd and
we wish to make that file descriptor the same as standard out. The
first step is to close standard out, and the duplicate the new fd
to standard out. Now, whenever we print to standard out it will
actually print to the file descriptor. Which is exactly what
happens when we run the program:
#> ./hello_dup hello #> cat hello Hello World!
You might notice, that this is the same as standard output
redirection in the shell using the > symbol, and, in fact, this
is how the shell implements that redirection.
3.2 Setting up a pipeline
Finally, we have all the information we need to set up a basic pipeline between two process that uses the stdin/stdout mechanisms. The procedure is straightforward, we need a pipe and the read and write ends are duplicated to standard output and input of the processes that are communicating.
Let's consider doing this for the simple program which will set up
a pipeline like so: parent | child. Here is such a program:
int main(int argc, char * argv[]){ int status; int pfd[2]; pid_t cpid; char c; //open a pipe, pfd[0] for reading, pfd[1] for writing if ( pipe(pfd) < 0){ perror("pipe"); return 1; } //Setup a pipe between child 1 and child 2, like: // parent | child cpid = fork(); if( cpid == 0 ){ /* CHILD 1*/ //close stdin close(0); //duplicate reading end to stdin dup2(pfd[0], 0); //close the writing end close(pfd[1]); //try and read 1 byte from stding and write stdout while( read(0, &c, 1) > 0){ //stdin now pipe! write(1, &c,1); //this is still stdout } exit(0); } else if ( cpid > 0){ /* PARENT */ //close stdout close(1); //duplicate writing end to stdout dup2(pfd[1], 1); //close reading end close(pfd[0]); //read and read 1 byte from stdin, write byte to pipe while( read(0,&c,1) > 0){ write(1, &c, 1); } //close the pipe and stdout close(pfd[1]); close(1); //wait for child wait(&status); }else{ /* ERROR */ perror("fork"); return 1; } return 0; }
First, a pipe is created before the fork. In the parent, standard out and the read end of the pipe are closed, and then the write end of the pipe is duplicated onto standard out. Whenever the parent writes to standard out, it is actually writing to the pipe. In the child, it similarly closes the write end of the pipe and standard in, and then duplicates the read end of the pipe to standard input. Now, whenver the child reads from standard input it is actually reading from the pipe, which the parent will write to.
It's a pipeline! Not a very useful pipeline. The parent reads its
data from standard input, sends it to the child through the pipe,
which writes the data to standard output. It's a glorified cat
program that requires two process, but a pipeline none the less. We
can see that it is doing that by running it in the command line:
#> ./pipe_dup hello hello ^Z [1]+ Stopped ./pipe_dup #> ps -o pid,pgid,comm PID PGID COMM 418 418 bash 4772 4772 emacs 5188 5188 ./pipe_dup 5189 5188 ./pipe_dup
The "hello" typed into the terminal was read by the parent, piped to the child, and then printed back to the terminal. If we stop the program and run ps, we can see that there are two processes running. It works! Now, the next step is implementing more complicated pipelines, which is a task for another lesson.