Lec 21: Network Fundamentals and Command Line Tools
Table of Contents
1 What is the internet?
The Internet by definition is a network of networks composed of computeres. As a non-technical term, we use the term Internet as a catchall for all connected computers, but in technical terms, it is just one part of a larger ecosystem of networks and protocols that enable the sharing of information.
This is not a class on networking or the internet, but the ability to communicate over a network is an integral part of modern operating systems. The programming interface provided byt he OS is called socket programming, and it provides a unified model for interacting with networked components. It is implemented by the operating system, within kernel, and there is a standard set of system calls used to request the O.S. to complete tasks.
But, to really understand network programming, you have to first have a decent understanding of the protocols that underly the Internet, and one thing you learn quickly about network programming is that the protocol is king. Understanding the protocols is will make you a better programmer.
1.1 Packet Switching
The internet is a packet switched network. A packet is defined as follows:

Figure 1: Packet with Header and Payload
All packets have a header, which stores the address or destination of a packet, and a payload which stores the data or message of the packet. The switching part of packet switching is that at network devices, like routers and switches, the packet arrives, and based solely on the header of the packet, the device knows where to send the data next. There are no pre-defined routs for data but the protocols ensure that the next hop in the path to the destination can be determined. As you might imagine, in such a model, addressing becomes very important.
1.2 The OSI Model and Protocol Stack
The Internet is modelled as a protocol stack where each protocol defines a different interaction layer. Information flows up and down the protocol stack, and at each layer, a different protocol comes to bare for forwarding the packet onward to the next hop.
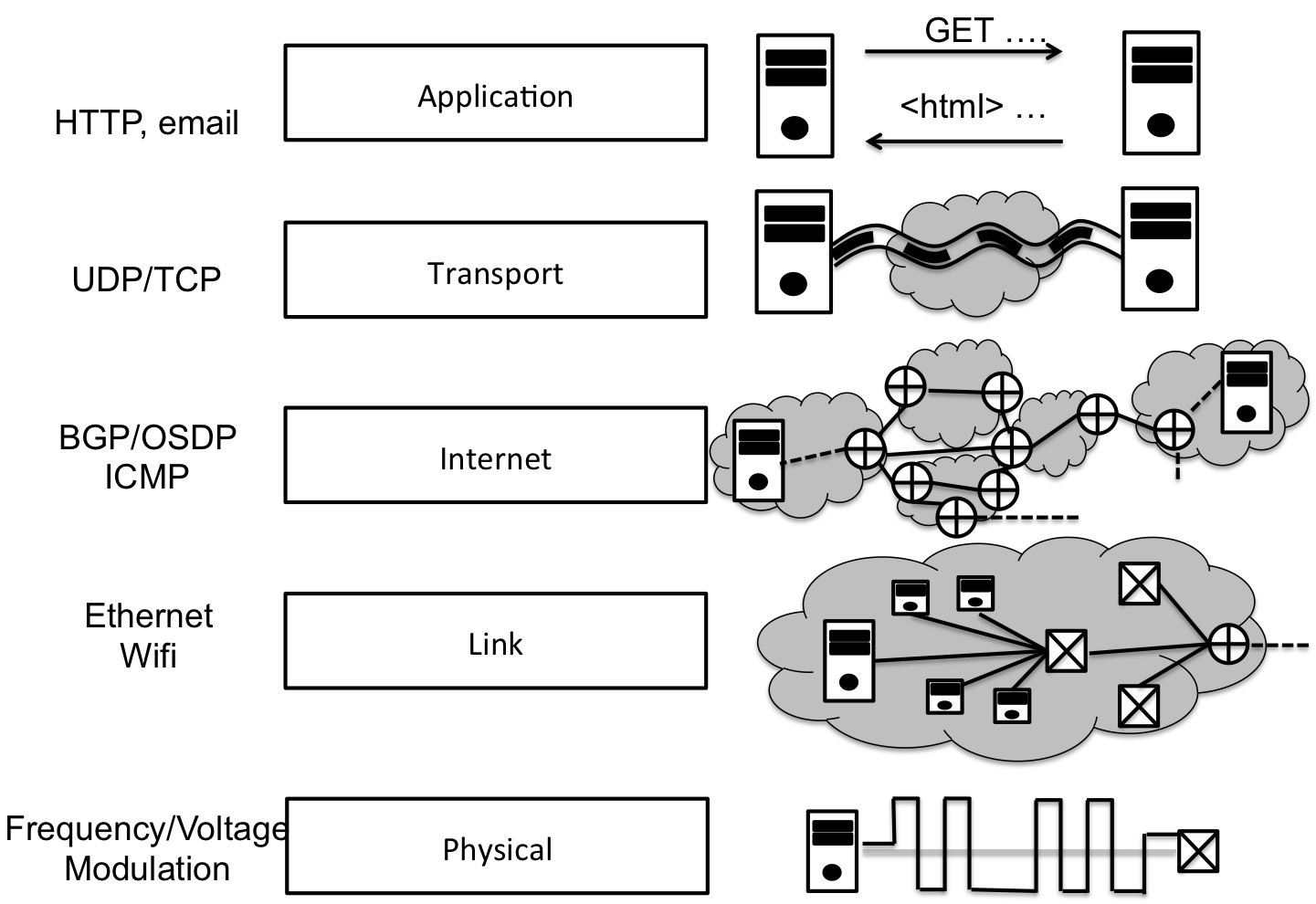
Figure 2: OSI Model and Protocol Stack
Each layer has different goal in mind. Starting with the physical layer, the main purpose is to actually transmit 1's and 0's over medium, like a wire. The link layer adds protocols for how the medium is shared across many connected devices, as well as error correction. An example of protocols on the link layer is ethernet or wifi.
The internet and transport layer of are particular interest in this class because you will interact directly with these protocol through their addressing schemes. The purpose of the internet layer is to inter-connect networks; for example, the USNA has a network, and if you want to send data to Google, your packets must traverse the USNA network and potentially many other federated networks before finally reaching a server at Google. The internet layer both describes the protocols for how networks inter connect with each other and the way that computers are identified, via the internet protocol address or ip address.
At a certain point, though, two processes running on different computers are actually sending and receiving data across the vastness of the Internet. The transport layer provides an abstraction for those two process to apear as if they are communicating directly with each other. Since many process can be communicating on the network at the same time, the transport layer also provides a mechanism, called ports, to differentiate communication destined for one process versus another.
Finally, at the application layer, additional protocols are available depending on the task at hand. For example, SMTP is used to transmit email messages and HTTP is used to download web content and BitTorrent is used to pirate music and videos :) From a generic programmers perspective, the application layer is the domain where we get to choose what data is sent and received and how that data is interpreted; the systems programming perspective also concerns itself with system calls that enable that communication.
2 Internet Addressing
Each layer has its own addressing scheme and information needed to perform routing/switching. This information is traditionally encoded within the header of the packet. There are two key addressing systems that we will use in this class, ip addresses and ports. Additionally, we also refer to computers by name, a domain name, which must be translated into an address.
2.1 IP addresses
An ip address is a 4-byte/32-bit number in Version 4 of TCP/IP protocol. We usually represented in a dotted quad notation:
4-bytes
_____________
/ \
192.168.128.101
\_/
|
1 byte
A byte is 8-bits, and thus can represent numbers between 0-255, which is why ip addresses do not have numbers greater than 255. The ip address is hierarchical where bytes to the left are more general while bytes to the right are more general. Based on a subset of the bytes, routers can determine where to send a packet next.
2.2 Domain Names and host
While IP addresses are somewhat usable, it is quite a burden to memorize the ip address of all the computers we might want to vist on the web. For exampel, while I might know the ip address of a single computer off hand, e.g., "10.53.37.142" is the ip address of a lab machine, I can't recall the ip address of Google or Facebook or much of anything else.
Instead, we use domain names to identify a networked device. A
hostname, is a dotted string of names, usually ending in the canonical
.com or .org or .edu or .gov or etc. For example, the domain
name for Google is google.com, but the Internet does not function on
domain names. It needs IP addresses. A separate protocol called the
Domain Name Service or DNS is tasked with converting domain names into
IP addresses.
2.2.1 host
We can access the DNS system on Unix through the host command. For
example, suppose we wanted to learn the IP address of google.com:
#> google.com google.com has address 74.125.228.110 google.com has address 74.125.228.103 google.com has address 74.125.228.96 google.com has address 74.125.228.99 google.com has address 74.125.228.104 google.com has address 74.125.228.101 google.com has address 74.125.228.102 google.com has address 74.125.228.97 google.com has address 74.125.228.100 google.com has address 74.125.228.105 google.com has address 74.125.228.98 google.com has IPv6 address 2607:f8b0:4004:803::1003 google.com mail is handled by 30 alt2.aspmx.l.google.com. google.com mail is handled by 40 alt3.aspmx.l.google.com. google.com mail is handled by 20 alt1.aspmx.l.google.com. google.com mail is handled by 10 aspmx.l.google.com. google.com mail is handled by 50 alt4.aspmx.l.google.com.
The output may not be what you expect. There are many, many different
IP addresses available to server google.com, and this is by intention
to balance the load of request across multiple machines. In fact,
every time you rerun host, you'll find that you get a different set
of IP address:
#> host google.com google.com has address 74.125.228.104 google.com has address 74.125.228.101 google.com has address 74.125.228.102 google.com has address 74.125.228.97 google.com has address 74.125.228.100 google.com has address 74.125.228.105 google.com has address 74.125.228.98 google.com has address 74.125.228.110 google.com has address 74.125.228.103 google.com has address 74.125.228.96 google.com has address 74.125.228.99 google.com has IPv6 address 2607:f8b0:4004:803::1003 google.com mail is handled by 50 alt4.aspmx.l.google.com. google.com mail is handled by 30 alt2.aspmx.l.google.com. google.com mail is handled by 40 alt3.aspmx.l.google.com. google.com mail is handled by 20 alt1.aspmx.l.google.com. google.com mail is handled by 10 aspmx.l.google.com.
If we were to query a less used domain name, one that isn't serving as
much traffic as google, we get IP addresses that are a bit more
sane. For example, let's see what the IP addresses are for www.usna.edu:
#> host www.usna.edu www.usna.edu is an alias for webster-new.dmz.usna.edu. webster-new.dmz.usna.edu has address 10.4.32.41
You can even use host to do a reverse DNS lookup, that is, lookup
the domain name based on an IP address:
#> host 10.4.32.41 41.32.4.10.in-addr.arpa domain name pointer webster-new.dmz.usna.edu.
2.3 Ports and /etc/services
The last bits of addressing relevant to this class is the port address. While the IP address is used to deliver packets to a destination computer, the port address is used to deliver the packets on the computer to the right process. Consider that a single computer all share the same IP address, there are many different applications using that connection at the same time. You might have multiple web pages open with email and playing games and etc, each of those interactions is performed by a separate process but all the data arrives at the computer through a single point.
The port address is a way for the Operating System to divide up the data arriving from the network based on the destination process. Additionally, ports tend to be tightly coupled with applications. For example, to initiate a HTTP connection for web browsing, you connect using port 80; to initiate a secure shell connection with ssh, you connect using port 22; and, to initiate a connection to send email, you connect using port 25, and so on. What makes ports important is that all those services, web server, ssh, and email, can all be running on the same computer. The ports allows the operating system differentiate traffic for each application.
2.3.1 /etc/services stores port application mappings
The mapping of ports to applications is deeply ingrained within the
Unix systems, and often many programs wish to quickly map a port to an
application. To assist in that process, most Unix system ship with a
list of the current standards in port mapping, which is stored in the
/etc/services file.
# Network services, Internet style # # Note that it is presently the policy of IANA to assign a single well-known # port number for both TCP and UDP; hence, officially ports have two entries # even if the protocol doesn't support UDP operations. # # Updated from http://www.iana.org/assignments/port-numbers and other # sources like http://www.freebsd.org/cgi/cvsweb.cgi/src/etc/services . # New ports will be added on request if they have been officially assigned # by IANA and used in the real-world or are needed by a debian package. # If you need a huge list of used numbers please install the nmap package. tcpmux 1/tcp # TCP port service multiplexer echo 7/tcp echo 7/udp discard 9/tcp sink null discard 9/udp sink null systat 11/tcp users daytime 13/tcp daytime 13/udp netstat 15/tcp qotd 17/tcp quote msp 18/tcp # message send protocol msp 18/udp chargen 19/tcp ttytst source chargen 19/udp ttytst source ftp-data 20/tcp ftp 21/tcp fsp 21/udp fspd ssh 22/tcp # SSH Remote Login Protocol ssh 22/udp telnet 23/tcp smtp 25/tcp mail time 37/tcp timserver time 37/udp timserver rlp 39/udp resource # resource location nameserver 42/tcp name # IEN 116 whois 43/tcp nicname tacacs 49/tcp # Login Host Protocol (TACACS) tacacs 49/udp re-mail-ck 50/tcp # Remote Mail Checking Protocol re-mail-ck 50/udp domain 53/tcp # Domain Name Server domain 53/udp mtp 57/tcp # deprecated tacacs-ds 65/tcp # TACACS-Database Service tacacs-ds 65/udp bootps 67/tcp # BOOTP server bootps 67/udp bootpc 68/tcp # BOOTP client (...)
This file continues on for some while, but the takeaway regarding the sheer expanse and variety of network applications is clear. Further, the use of ports to different one service from another is vital to providing the diversity of services.
3 The Client-Server Connection Model and Transport Protocols
Most interactions of applications are dictated by the client-server model. In this model there exists clients who are requesting a services for a server.
Figure 3: Client Server Model
In the model, we describe clients as connecting to servers and servers listening to incoming connections. When a connection is established, or data is received, the server replies to the client with data as required by the application protocol.
While this class will focus on the client server model, there are other models of network interaction. For example, the peer-to-peer model is when clients act as both client and servers. This is common for many distributed systems, such as BitTorrent or Skype.
3.1 Reliable Transport: TCP or SOCKSTREAM
The client server model fits into the protocol stack at the transport layer. There are typically two types of transport available for programmers, reliable and unreliable transport. Interestingly, none of the protocols in lower layers ensure any reliability — at any time packets can be drop, misrouted, delayed, or generally deformed without notice. The fact that such things can happen on the network is actually a positive because the lower layers can be much more efficient without having to worry about reliable delivery.
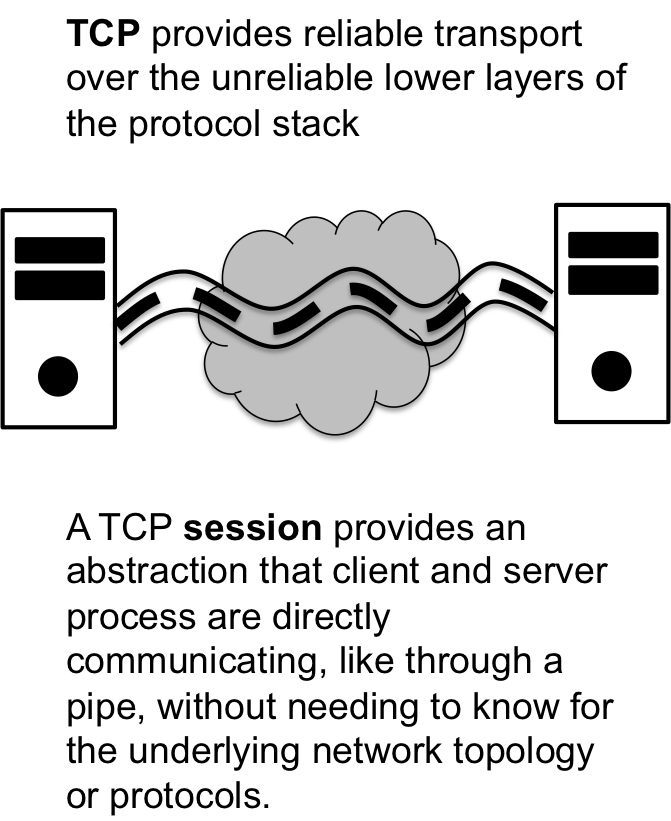
Figure 4: TCP Session
The TCP or Transmission Control Protocol was developed to provide
reliable transport on the inherently unreliable lower layer packet
deliver system. The big idea behind TCP is that it establishes a
stream or session between client and server where the expectation
of packet delivery and acknowledgment forms the basis of reliable
transport mechanism. Essentially, when you are using TCP it is as if
the client and server are communicating directly with each other, like
via a pipeline, even though there may potentially be a huge network
between them. In the parlance of socket programing, which we will
discuss in the next lesson, TCP protocol is described as a
SOCKSTREAM because it proves a stream of information, much like a
pipeline.
3.2 Unreliable Transport: UDP or DATAGRAM
Reliable transport has a cost, though. The cost is the retransmission of lost or deformed packets and acknowledgements of properly received packets. In order to have reliable transportation, all information must be properly acknowledged upon receipt and if a packet was not properly received, then it must be retransmitted. The result is that there exists a significant overhead, and this is worsened by the fact that not all communication needs to be reliable — dropping a few packets here and there never killed anyone, yet.
The complementary protocol to TCP is UDP or Universal Datagram
Protocol, which is an unreliable transport mechanism. The UDP
protocol, or DATAGRAM protcol, does not make any guarentees about
the delivery if a packet. It might get there … or it might
not. Datagram protocols are not session driven either; without
reliability, the client and the server need not stay in sync to ensure
that all messages are acknowledged. Instead, a server just listens for
incoming data from clients and thats that.
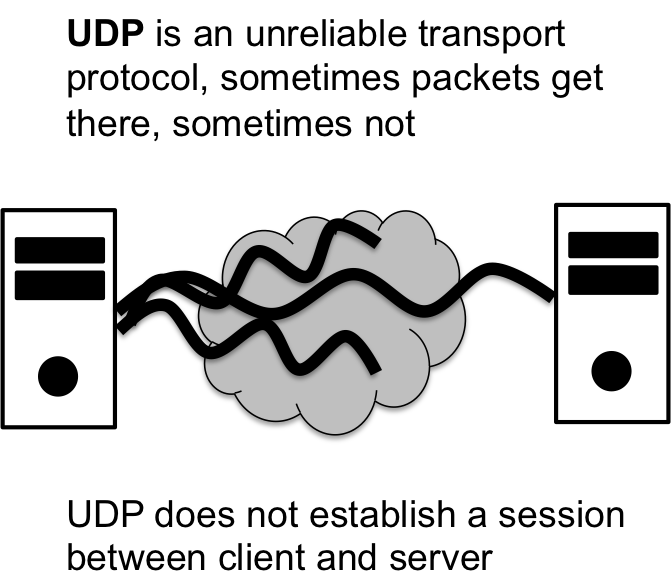
Figure 5: UDP
You might be wondering when would this ever be useful? UDP is quite common for a number of applications; for example, live audio streams. There is no need for audio streams to be reliable, if you miss a packet, so what, you'll just get the next one and keep playing the music. However, if you were to do this reliably, you'd have to stop the music while missed data was retransmitted, and the result is you might keep getting further and further behind in the live stream.
4 Networking Command Line Tools
Rather then jump into the details of socket programming, we can explore some Unix command line tools. As a programmer, these tools are often indispensable for debugging and understanding the functionality of your program.
4.1 netcat : the network "swiss army knife"
The netcat program has often been described as the "swiss army
knife" of networking because it can do anything and
everything. It's pretty amazing once you get into the details, but
its more basic functionality is fairly useful already for our
purposes. We'll see how to use it as both a client and server using
both UDP and TCP protocols.
4.1.1 netcat client
When working as a client, netcat takes two arguments:
netcat dest port
The dest is a destination address, which can either be a IP
address as a dotted quad or a domain name. The port is a number
representing the port address. This is all we need to make
netcat act like a web client, so let's connect to a web server
#> netcat www.cnn.com 80 GET /index.html <!DOCTYPE HTML> <html lang="en-US"> <head> <title>CNN.com - Breaking News, U.S., World, Weather, Entertainment & Video News</title> <meta http-equiv="content-type" content="text/html;charset=utf-8"/> <meta http-equiv="last-modified" content="2014-04-03T13:48:56Z"/> <meta http-equiv="refresh" content="1800;url=http://www.cnn.com/?refresh=1"/> <meta http-equiv="X-UA-Compatible" content="IE=edge"/> <meta name="robots" content="index,follow"/> (...)
What we've just done is establish a TCP connection on port 80, the HTTP port for web traffic, and make a request to the HTTP server to send us the main page for cnn.com. And it works!
4.1.2 netcat server
netcat can also act as a sever by listening for incoming
connections on a given port. You do this with the -l command:
#> netcat -l 1845
There is now a service running on 1845, netcat, and we can
connect to it using another netcat client.
#> netcat -l 1845 Hello What's your name? adam me too, how strange. strange ...... #>
#> netcat localhost 1845 Hello What's your name? adam me too, how strange. strange ...... ^C #>
The domain name localhost refers to the current computer, this
way we don't always ahve to remember the IP address. In the above
example, information is typed back and forth between the netcat
servers and clients.
4.1.3 netcat UDP
To use the UDP, the -u flag is used. Let's start by establishing a
server listing for incoming UDP datagrams on port 1845.
$ netcat -u -l 1845 Hello hello testing Anyone still out there? ..
#> netcat -u localhost 1845 Hello hello testing ^C #>
Notice in the example, information was flowing back and forth, but once the client terminated, the server continues. No session was established so how would the server even know anything happened. The server even sends a UDP packet, the final message, "Anyone still out there?" and it is sent but just dropped without notice.
4.2 netstat : monitor current connections
The other very useful command for Unix uses is nestat, which
displays a list of information about current network usage on the
computer. It's best to just see an example.
Suppose in one terminal, I've created a netcat server.
netcat -l 1845
We can see that this was properly established by vieing the netstat
output with the -l flag, indicating we are interested in listening
servers. We will also use -n flag so all port numbers are displaed
#> netstat -ln Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:36688 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:1845 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:44469 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:25 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:538 0.0.0.0:* LISTEN tcp6 0 0 :::55662 :::* LISTEN tcp6 0 0 :::591 :::* LISTEN tcp6 0 0 :::111 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:631 :::* LISTEN tcp6 0 0 :::25 :::* LISTEN tcp6 0 0 :::39612 :::* LISTEN udp 0 0 0.0.0.0:57189 0.0.0.0:* udp 0 0 0.0.0.0:68 0.0.0.0:* udp 0 0 0.0.0.0:111 0.0.0.0:* udp 0 0 10.53.33.232:123 0.0.0.0:* udp 0 0 127.0.0.1:123 0.0.0.0:* udp 0 0 0.0.0.0:123 0.0.0.0:* udp 0 0 0.0.0.0:538 0.0.0.0:* udp 0 0 0.0.0.0:601 0.0.0.0:* udp 0 0 0.0.0.0:33370 0.0.0.0:* udp 0 0 127.0.0.1:608 0.0.0.0:* udp 0 0 0.0.0.0:49817 0.0.0.0:* udp 0 0 0.0.0.0:5353 0.0.0.0:* udp6 0 0 :::35113 :::* udp6 0 0 :::47936 :::* udp6 0 0 :::56801 :::* udp6 0 0 :::111 :::* udp6 0 0 ::1:123 :::* udp6 0 0 fe80::d227:88ff:fed:123 :::* udp6 0 0 :::123 :::* udp6 0 0 :::601 :::* udp6 0 0 :::5353 :::* (...)
There is quite a lot of output, but at the top is the good
stuff. What you can see is the combination of IP address (0.0.0.0 and
127.0.0.0 indicating localhost) and port that are curently being
listend on by services. If you look closely, you can see that, yes,
the netcat listening on port 1845 is present.
Let's look at the output when we connect the client netcat
#> netcat localhost 1845
This time we run netcat without the -l flag because we are
interested in established connections.
#> netstat -n Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 160 10.53.33.232:22 10.53.33.254:57078 ESTABLISHED tcp 1 0 10.53.33.232:47982 91.189.89.144:80 CLOSE_WAIT tcp 0 0 127.0.0.1:41217 127.0.0.1:1845 ESTABLISHED tcp 0 0 10.53.33.232:22 10.53.33.254:54510 ESTABLISHED tcp 0 0 127.0.0.1:1845 127.0.0.1:41217 ESTABLISHED tcp 0 0 10.53.33.232:801 10.1.83.18:2049 ESTABLISHED tcp 0 0 10.53.33.232:22 10.53.33.254:58882 ESTABLISHED tcp 0 0 10.53.33.232:48491 10.1.68.11:445 ESTABLISHED (...)
Looking through the list, we find 127.0.0.1:1845 which is our
netcat server is connected to 127.0.0.1:54510, which is our
netcat client. The same entry is also found in reverse, client->server.
Now, something might seem a bit off with this because both client and server were using the same port, which is true, but that is for establishing a connection. A server must be listening on a given port so that it can be reached, but once the connection is established, the port doesn't matter as long as client and server can talk to each other. In fact, a random port is chosen, in this case 54510, to facilitate that communication, and we'll see this in action when we discuss socket programming in detail in the following lessons.